This post have got access from the original author Avihay Assouline to translate into Chinese. If you are interest in this article and want to repost it, you should add the refer link to this article in your repost.
这篇文章已从英文原作者Avihay Assouline那里得到翻译授权,如果你对本文感兴趣而且想转发,你应该在转发文章里加上本文的链接。
深度学习与App的魔幻结合
打造你自己的自动驾驶汽车的第一步,是教会你的App从18000张图片中识别交通灯

机器学习是发展最快和最令人兴奋的领域之一,而其中最有代表性的是深度学习。自从我回到大学,我一直专注于这个领域。然而,在2009年的时候,软硬件和数据并不能达到实现深度学习的要求。但是,自从那以后,这些都不再是问题。
在这个简短的入门指南中,我将会通过深度学习的一些基本步骤,示范一下如何自己入门深度学习。我们将开发一款使用现场相机数据来识别交通灯的app。
在我们开始学习之前,我想说明一下一些事情。这个入门教程会跳过一些概念和难点,以便于降低入门门槛和尽快实现真实测试。另外,我们将只使用深度学习中的图片分类,以使整个入门过程变得更加直接和简单。
简介
在这里我假设你对深度学习有一定了解。你可能见过一些使用了深度学习的产品,比如Facebook的脸部识别,Apple的Siri,Mobileye的车辆碰撞识别等等。然而,随着最近深度学习框架的开源,不仅仅巨头们可以开发这些产品,创业公司现在也可以参与其中。例如, Clarifai 为你的应用提供了视觉能力, AIDoc 对医学放射工业发起了挑战。这些可以看出使用场景正在改变。
深度学习
什么是深度学习?什么是神经网络?我可以在这里讨论一下这些。但是,我更希望你看看这个由吴恩达讲解的深度学习的视频。虽然这段视频有点长,但是吴恩达提供了一些很好的例子和讲解。
如果你没有时间去看完这段视频,这里有一些里面说的的重点:在过去,为了让我们的电脑能够执行不同的任务,我们不得不为每个小问题单独编写算法。机器学习的强大之处在于,它能够使用同一种算法进行学习。它能够自己发现问题的关键和尝试自己去解决问题。在这个教程中你可以看到,除了提供数据给算法,我们几乎没有改变任何东西,然而它却能自己学习一个新的概念:交通灯。
训练过程
训练我们自己的深度学习神经网络,是实践学习算法的一步。我们提供一个图片分类的数据集给算法,希望它学习如何分类不属于训练数据集的新图片。
假设我们能够获得所需要的数据(这里称为“训练集”),用于训练我们的算法。然而,像人类一样,算法在训练期间是需要对其行为进行反馈的。为了实现对算法的行为反馈进行验证,我们需要为算法提供一个叫“验证集”的独立数据集。
在完成训练以后,我们将使用“训练集”中没有的数据作为输入数据,并看看它的表现如何。你猜对了,我们将需要第三个被称为“测试集”的数据集,这个数据集将会帮我们测试出算法的识别精确度。
我们总共需要3个不同的数据集:训练,验证,测试。
迁移学习
在实践中,我们不会经常从零开始训练我们的深度学习网络。因为现实中,很难找到足够大的数据集来做一些复杂任务,例如图片分类。
一般来说,我们会直接使用经过大量数据训练的网络作为初始的深度学习网络。在我们这个例子中,我们使用了一个经过一百万张图片训练的预训练神经网络,并用它来从20000张图片中学习新的分类。
这个小技巧确实有效,作为分类问题的一部分是共通的,例如识别边缘,颜色,甚至形状。
移动设备的机遇
如果你对现今的世界足够关注,你就能理解数据才是深度学习中最重要的东西。没有足够数量的数据,我们的算法将不能根据问题去学习并产生令人满意的结果。
这里有一个对于移动开发者来说非常巨大的机遇。全世界超过20亿设备不断提供各种不同类型的数据,这是非常有可能去开发一款应用去收集高质量数据,用于训练和学习。很多成功的创业公司都是围绕这个想法而建立的。
使用Caffe进行深度学习
Caffe
Caffe 是一个由Berkeley Visio和学习中心(BVLC)以及社区贡献者一同开发的深度学习框架。这个框架被世界范围内的计算机视觉研究者使用。尽管这是一个主要为计算机视觉开发的框架,然而他可以做其他很多深度学习的工作。
DIGITS
英伟达的 DIGITS 使用了web交互界面简化了深度学习的一般步骤,例如:
- 数据集管理
- 在多GPU系统中设计和训练神经网络
- 通过先进的虚拟化进行实时性能管理
DIGITS 交互非常简单,开发者只需要专注于神经网络的设计和训练,不需要投入太多精力到编程和调试。
硬件要求
训练深度神经网络是一项计算密集型的工作。虽然你可以只通过只有CPU的机器来运行,但是事实上你更需要一个拥有GPU(例如英伟达的GTX系列,$500 - $700)的性能强大的机器来运行神经网络。
如果你没有这样一个性能强大的机器,你可以从亚马逊那里租一个。例如你可以从spotinst这里获取相关的服务,而且只需要 0.2 美元/小时。如果你需要更多的帮助,可以联系我。
开发一个识别交通灯的App
这里我们开始开发一个你之前在视频中看到的能识别交通灯的app。没什么需要担心的,所有的代码都在Github上开源。
为了继续这个教程,你应该先安装Caffe和DIGITS。在这个教程中,我们将直接使用DIGITS的web交互界面,因此不需要在学习其他任何语言或框架。
通过使用Caffe & DIGITS,我们在一个预训练的网络中实施迁移学习,并教会它红绿交通灯的新概念。然后,我们将把经过训练的网络应用到我们一个简单的移动应用中。
交通灯数据
很多创业公司和有开创精神的组织开源了一些非常有用的训练集。其中有一些设立了一些能赢取奖金的比赛,例如Udacity,Kaggle等。
为了让这个简单应用运行起来,我将会使用Nexar的 Challenge #1 数据集。这个数据集包括 18,659 个标有交通灯的图片。针对每张图片,有人手动标记了包含的是红灯还是绿灯或者没灯。在这个简单应用中,我们只关注图片是否存在交通灯,不关心交通灯的位置或其他。

训练
为了这个应用能正常使用,我们将从GoogLeNet做一次迁移学习。幸运的是,DIGITS的标准网络中已经包含了这个。我们只需下载预训练caffmodel文件并用DIGITS打开即可。
非常幸运,我有权限使用一个强大的机器,这个机器专门用来做VR体验,而且拥有一个运行在Ubuntu 14.04 平台上的GTX 1070 GPU。对于一些人来说,看着训练过程一定是非常无聊的,特别当你看到精度不断提高时。
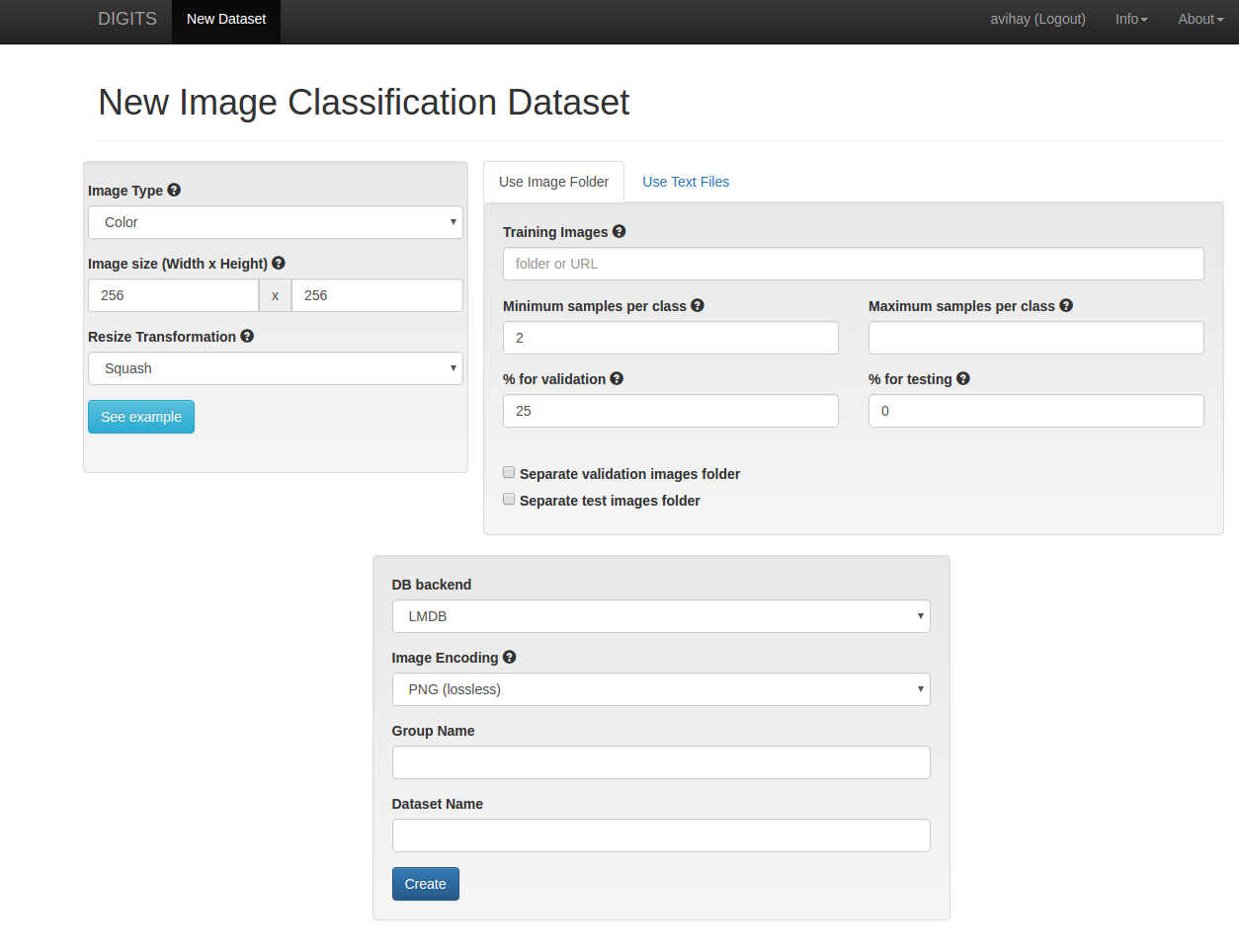
第一步,建立训练/验证/测试 数据集。DIGITS 提供一个便捷的方法。DIGITS根据它们的标签和你将要检验和测试的数据划分百分比,将所有样本,划分到不同的目录。在我们的例子中,我们直接将DIGITS 一个目录划分为三个子目录:红,绿和背景。
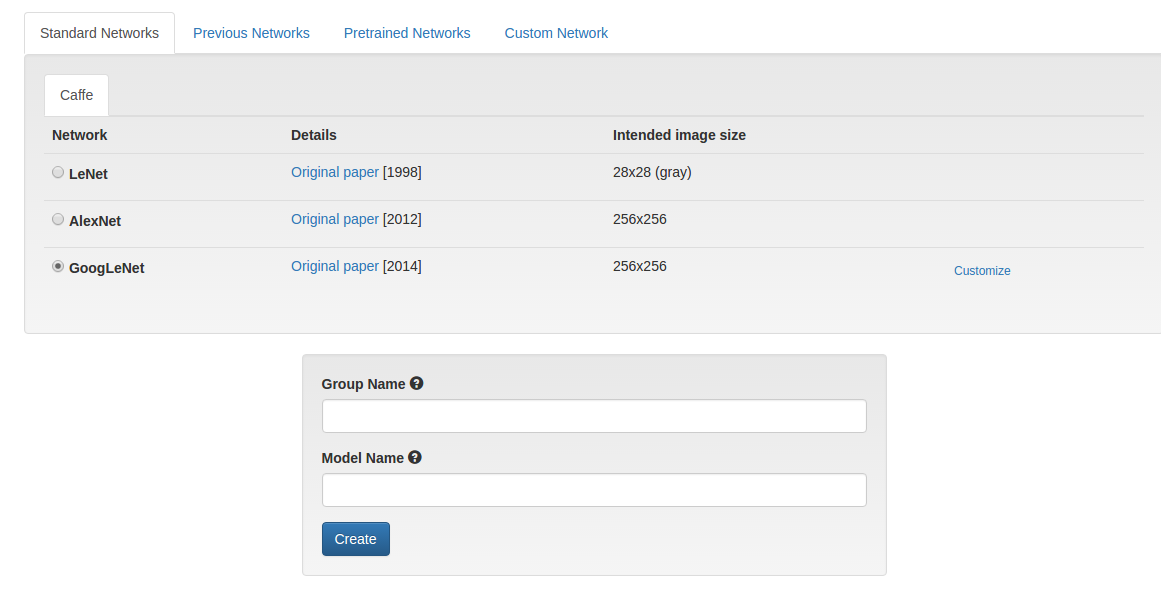
第二步,建立模型。DIGITS 已经包含了我们想要的GoogLeNet神经网络。GoogLeNet已经通过训练能够将图片分成1000个不同的类别。在我们的例子中,为了让它能识别3种新的类型,我们需要对它进行一些改进。不要担心,这些只是一些简单的文本改动。
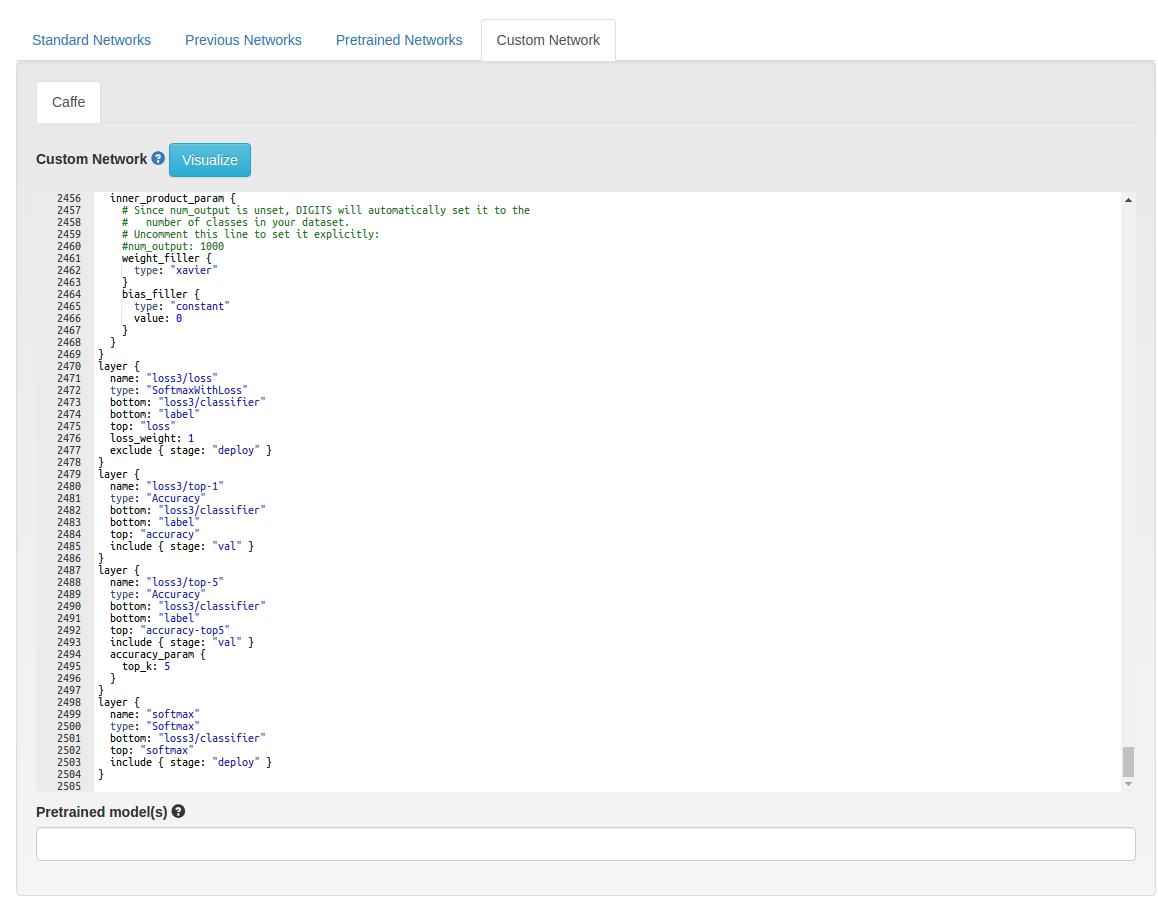
我们要做的改动是非常简单的: 查找/替换 所有出现loss1/classifier, loss2/classifier 和 loss3/classifier,并加上后缀‘/retrain’。例如 loss{x}/classifier 变成
loss{x}/classifier/retrain— 。 我们做这一步是为了让我们的神经网络重新学习,因为这新的部分与之前1000种分类都不同。
为了能运行迁移学习,我们将使用预学习网络信息(又称权重),而这只需让DIGITS 下载 bvlc_googlenet.caffemodel 这个预训练 caffe 模型即可。
值得庆贺,你现在已经做好了训练网络的准备了。
根据默认的训练设置, DIGITS 迁移学习能生成一个在验证集中精度达到 93.1% 的神经网络。难道这不令人兴奋吗?我们很难做到这一点:)
训练完成之后,我们可以通过DIGITS下载我们的模型,然后获取我们使用该模型开发移动应用的必要数据。
开发应用
幸运地,由于Aleph7和noradaiko做了一些基础集成 ,我很容易的就可以将 Caffe 运行在iOS上。除了使用这些基础集成来作为我们的项目的开始,我们还要改进一下,以便它在相机的现场视频流中能正常运行。
这段代码非常简单,让我们来看一下 ViewController.mm 文件中最重要的部分:
NSString *netDefinition = [NSBundle.mainBundle pathForResource:@"deploy"
ofType:@"prototxt"
inDirectory:@"model"];
NSString *netWeights = [NSBundle.mainBundle pathForResource:@"model"
ofType:@"caffemodel"
inDirectory:@"model"];
NSString *datasetMean = [NSBundle.mainBundle pathForResource:@"mean"
ofType:@"binaryproto"
inDirectory:@"model"];
NSString *netLabels = [NSBundle.mainBundle pathForResource:@"labels"
ofType:@"txt"
inDirectory:@"model"];
string net_definition = string([netDefinition UTF8String]);
string net_weights = string([netWeights UTF8String]);
string dataset_mean = string([datasetMean UTF8String]);
string net_labels = string([netLabels UTF8String]);
classifier = new Classifier(net_definition,
net_weights,
dataset_mean,
net_labels);
我们通过DIGITS下载的文件model.caffemodel, mean.binaryproto, labels.txt 和 deploy.prototxt ,创建一个新的分类器。
cv::Mat src_img, bgra_img;
UIImageToMat(image, src_img);
cv::resize(src_img, src_img, cv::Size(224, 224));
cv::cvtColor(src_img, bgra_img, CV_RGBA2BGR);
vector<Prediction> result = classifier->Classify(bgra_img, 3);
我们需要输入各种尺寸的数据进行分类。为了做到这一点,我们需要把我们的UIImage对象转换为OpenCV的矩阵(第2行),改变其大小以适应我们的网络,然后把颜色序列从 RGBA 转换成 BGR。因为Caffe需要这样的输入格式,所以我们需要先做这个转换。另外,你可能注意到,当进行分类时,这里有一个魔术数字‘3’。这表示的是你数据集分类的数量 - 在我们这个例子中,表示:绿,红,背景。
for (vector<Prediction>::iterator it = result.begin(); it != result.end(); ++it) {
NSString* mylabel = [NSString stringWithUTF8String:it->first.c_str()];
NSNumber* probability = [NSNumber numberWithFloat:it->second];
if (it == result.begin() && probability.floatValue > 0.6) {
_lightImage.image = [UIImage imageNamed:[labelToImage valueForKey:mylabel]];
}
}
接下来,我们只需重复识别和捕获最高确定性的识别。如果它通过了一些阀值(当前设定为 60% 确定性)我们将用正确的交通灯图片更新我们的UI。
准备去让你的数据跑起来吗?非常好!
你必须做的的所有事情,只是改变了一开始训练的样本和改变分类的数目。其他所有的东西都是不变的。
这是关于这个app的另外一段短视频:
我能在我的线上App上用它吗?
当然,最好不。至少我现在不推荐。这个有点例子太过于笨拙以至于不适合直接使用。
你应该在你桌面之外使用这个项目,去体验和测试你的算法,这是一种不需要编码就能测试你的POC项目的好方法。你也可以用它来开发快速应用,去收集你在训练过程中输入的新数据。
一旦你掌握了这个训练过程,你接下来将很容易的过渡到学习TensorFlow,或其他需要对深度学习有更深入理解的框架,例如 BrainCore。
如果你喜欢这篇文章,并且想继续关注,请点击 ♥ (喜欢) - 这将是我继续下一篇的动力!
你也可以在Twitter中关注英文原文作者。
如果你喜欢这篇译文,记得在简书中给我点赞并关注我哦
本文Github地址
