本篇翻译自Denny Britz(Google Brain Team成员)的RNN系列教程
RNN也就是Recurrent Neural Network,在语音识别,自然语言处理(NLP)等很多领域广泛应用,人气很高。这个系列教程包含以下:
1、RNN简介(本文)
2、使用Python和Theano实现RNN
3、了解方向传播算法和梯度消失问题
4、实施GRU/LSTM RNN
本文假设你对基本的神经网络有所了解。
什么是RNN?
RNN是按照时间维度的展开,代表信息在时间维度从前往后的的传递和积累,后面的信息的概率建立在前面信息的基础上,在神经网络结构上表现为后面的神经网络的隐藏层的输入是前面的神经网络的隐藏层的输出。
假定所有输入(输出)是相互独立的,那这对于许多任务来说是扎心的。比如你想预测一个句子中的下一个单词,单词之间都独立还预测个DD,跟妹子陌路,还想拉拉小手。另外RNN称为循环因为它们是对序列的每个元素执行相同的任务,输出取决于先前的计算。考虑RNN的另一种方法是,它们有一个“记忆”,捕获到目前为止所计算的信息。在理论上RNN可以以任意长的序列来使用信息,但在实践中,它们仅限反向几步。一个典型的RNN:

上图显示了RNN正展开成一个完整的网络。展开意味着我们写出了完整序列的网络。例如,如果我们关心的序列是5个字的句子,则网络将被展开为5层神经网络,每个单词一层。RNN中计算的公式如下:
Xt是输入t的时间步长。X1可以是对应于句子的第二个单词的ont-hot 向量。
St是时间t时的隐藏状态。它是构建网络的“记忆”。St是基于以前的隐藏状态和当前步骤的输入计算的:st = f(Uxt + Wst-1)。该函数F通常是非线性的,如tanh或ReLU。 s-1存在是为了计算第一个隐藏状态,通常全被初始化为零。
Ot是在t时的输出。例如,如果我们想预测一个句子中的下一个单词,会输出一个词汇概率的向量。
ot = softmax(Vst)。
这里有几件事要注意:你可以将隐藏状态ST视为网络的记忆。ST捕获所有先前time step中的信息。在时间t可以根据时间记忆计算出输出Ot。如上所述,在实践中有点复杂,因为ST通常无法从太长的时间捕获信息。
不同于传统的深层神经网络,其在每个层使用不同的参数,RNN 在所有步骤中共享相同的参数(U,V,W)。这反映了我们在每个步骤上执行相同的任务,只用不同的输入。那这大大减少了我们学习的参数数量。
上述图表在每个time step都有输出,但是根据任务,这不是必需的。例如,当预测句子的情绪时,我们可能只关心最终输出,而不是每个单词之后的情绪。类似地,我们可能不需要在每个time step都有输入。RNN的主要特征是它的隐藏状态并且能捕获有关序列的一些信息。
RNN可以做什么?
在许多NLPtask中,RNN已经取得了巨大的成功。与此同时也想到了LSTM,是的它的长期依赖性要好于RNN。不用担心的是LSTM与本教程中将要开发的RNN基本上是一样的,它们只是具有不同的计算隐藏状态的方法。我们将在稍后的文章中更详细地介绍LSTM。以下是NLP中RNN的一些示例应用。
语言建模和生成文本
给定一系列单词,我们想预测并给出先前任一单词的概率。语言模型允许我们去衡量句子相似性,这是机器翻译的重要输入(因为高概率句子通常是正确的)。在能够预测下一个单词时会有一个slider-effect,它会得到一个生成模型,允许我们从输出概率中抽样生成新的文本。根据我们的训练数据,我们可以生成各种各样的东西。在语言建模中,我们的输入通常是一系列单词(例如,编码为one-hot),我们的输出是预测单词的序列。我们构造ot = xt + 1可以在step t中的输出单词是实际中我们想要的。
关于语言建模和生成文本的研究论文:
机器翻译
机器翻译类似于语言建模,因为我们的输入是一系列单词(例如德语),输出的是一系列的单词(比如中文)。一个关键的区别是,我们的输出只有在我们看到完整的输入之后开始,因为翻译的句子的第一个单词可能需要从完整输入序列中才能获取。

机器翻译研究论文
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
语音识别
给定来自声波的声信号的输入序列,我们可以预测语音段的序列及其概率。
关于语音识别的研究论文:
生成图像说明
与卷积神经网络一起,RNN已被用作模型的一部分,以生成未标记图像的描述。这是非常惊人的,这似乎是有效的。组合模型甚至将生成的单词与图像中发现的特征对齐。
如何训练RNN
看了上面,RNN这么牛逼,那么怎么实现呢,不要着急,其实它类似训练传统的神经网络,我们也使用反向传播算法,不过是变化了下,由于参数由网络中的所有time step共享,每个输出的梯度不仅取决于当前time step的计算,而且还取决于以前的tiem step。例如,计算t = 4的梯度我们需要按照时间序列反向计算3个然后累加起来就是第四个时间的梯度,这称为基于时间的反向传播算法(BPTT)。要注意的是:RNNs的当层级比较多时(相距很远的步骤之间存在依赖关系)由于梯度消失/爆炸问题在训练上会存在一定的学习困难。当然,在业内也设计了一些类型(如LSTMs)避开这些问题。
RNN扩展
多年来,研究人员开发了更复杂类型的RNN来处理RNN模型的一些缺点。我们将在稍后的文章中更详细地介绍这些内容,但是我希望本节作为简概,可以让读者熟悉一些模型的分类。
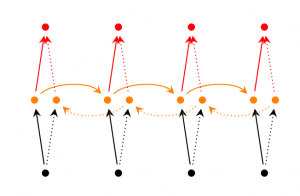
- 双向RNNs(Bidirectional RNNs) 是一种当前时刻不仅仅取决于以前时刻同时还取决于未来时刻的RNN变体。举个例子, 比如我的一段文本不仅仅和前面有关系, 还和后面有一定的关系,要预测序列中缺少的单词,你要查看左侧和右侧上下文。双向RNN非常简单,你理解两个堆叠在一起的RNN。然后基于两个RNN的隐藏状态来计算输出。
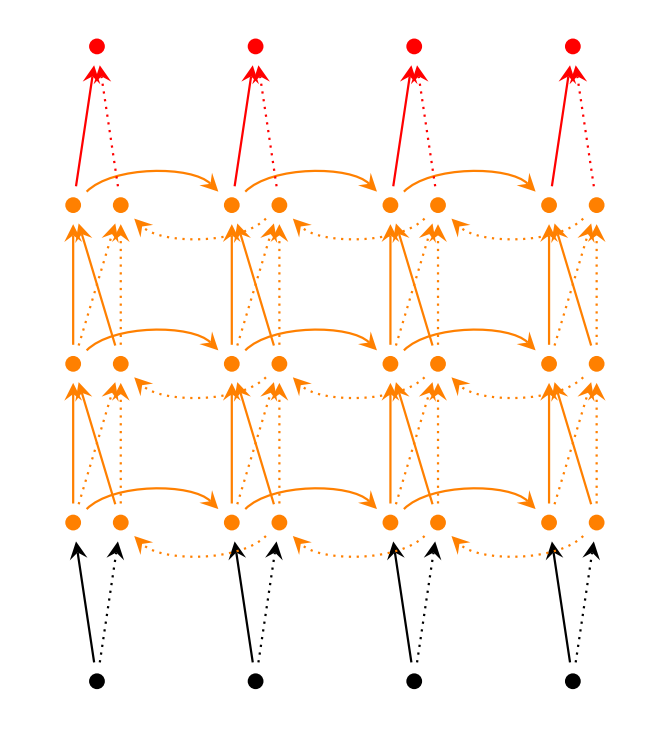
- LSTM RNNs(LSTM networks)是近几年比较火的一种RNN变体, 实际上也是运用最为广泛的一种形式, 它克服了梯度衰减问题, 这个问题在NN中也同样存在, LSTM本身也有变体, 至少不下十几种形式, 但是本质都差不多.
我的
简书地址
uqlai`blog
扩展阅读:
循环神经网络(Recurrent)——介绍
