
Issue (11): 2979-2984,2992 DOI:10.11772/j.issn.1001-9081.2016.11.2979

引用本文

陆中秋, 侯振杰, 陈宸, 梁久祯. 基于深度图像与骨骼数据的行为识别[J].计算机应用, 2016, 36(11): 2979-2984,2992.DOI:10.11772/j.issn.1001-9081.2016.11.2979.

LU Zhongqiu, HOU Zhenjie, CHEN Chen, LIANG Jiuzhen. Action recognition based on depth images and skeleton data[J]. Journal of Computer Applications, 2016, 36(11): 2979-2984,2992. DOI:10.11772/j.issn.1001-9081.2016.11.2979.

基金项目
国家自然科学基金资助项目(61063021);江苏省产学研前瞻性联合研究项目(BY2015027-12)
通信作者
侯振杰(1973-), 男, 内蒙古包头人, 教授, 博士, CCF会员, 主要研究方向:机器视觉、机器学习,houzj@cczu.edu.cn
作者简介
陆中秋(1991-), 男, 江苏张家港人, 硕士研究生, CCF会员, 主要研究方向:行为识别;
陈宸(1982-), 男, 江苏常州人, 博士, 主要研究方向:数字图像处理、机器学习;
梁久祯(1968-), 男, 山东济南人, 教授, 博士, CCF会员, 主要研究方向:机器视觉
文章历史
收稿日期:2016-06-07
修回日期:2016-06-27
ContentsAbstractFull textFigures/TablesPDF
基于深度图像与骨骼数据的行为识别


常州大学 信息科学与工程学院, 江苏 常州 213164
收稿日期:2016-06-07 ;修回日期:2016-06-27
基金项目:国家自然科学基金资助项目(61063021);江苏省产学研前瞻性联合研究项目(BY2015027-12)
作者简介:陆中秋(1991-), 男, 江苏张家港人, 硕士研究生, CCF会员, 主要研究方向:行为识别;
陈宸(1982-), 男, 江苏常州人, 博士, 主要研究方向:数字图像处理、机器学习;
梁久祯(1968-), 男, 山东济南人, 教授, 博士, CCF会员, 主要研究方向:机器视觉
通讯联系人:侯振杰(1973-), 男, 内蒙古包头人, 教授, 博士, CCF会员, 主要研究方向:机器视觉、机器学习,houzj@cczu.edu.cn
摘要: 为了充分利用深度图像与骨骼数据进行人体行为识别,提出了一种基于深度图形与骨骼数据的多特征行为识别方法。该算法的多特征包括深度运动图(DMM)特征与四方形骨骼特征(Quad)。深度图像方面,将深度图像投影到一个笛卡尔坐标系的三个平面获得深度运动图特征。骨骼数据方面,提出四方形骨骼特征,它是骨骼坐标的一种标定方式,得到的结果只与骨骼姿态有关。同时提出一种多模型概率投票的分类策略,减小了噪声数据对分类结果的影响。所提方法在MSR-Action3D和DHA数据库进行实验,实验结果表明,所提算法有着较高的识别率与良好的鲁棒性。
关键词:深度图像骨骼数据行为识别深度运动图四方形骨骼特征
Action recognition based on depth images and skeleton data
LU Zhongqiu,HOU Zhenjie,CHEN Chen,LIANG Jiuzhen


School of Information Science & Engineering, Changzhou University, Changzhou Jiangsu 213164, China
Background: This work is partially supported by the National Natural Science Foundation of China (61063021), Industry, Teaching and Research Prospective Project of Jiangsu Province (BY2015027-12)
LU Zhongqiu, born in 1991, M. S. candidate. His research interests include action detection, machine learning.
HOU Zhenjie, born in 1973, Ph.D., professor. His research interests include computer vision, machine learning
CHEN Chen, born in 1982, Ph.D.. His research interests include signal and image processing
LIANG Jiuzhen, born in 1969, Ph.D., professor. His research interests include computer vision
Abstract: In order to make full use of depth images and skeleton data for action detection, a multi-feature human action recognition method based on depth images and skeleton data was proposed. Multi-features included Depth Motion Map (DMM) feature and Quadruples skeletal feature (Quad). In aspect of depth images, DMM could be captured by projecting the depth image onto the three plane of a Descartes coordinate system. In aspect of skeleton data, Quad was a kind of calibration method for skeleton features and the results were only related to the skeleton posture. Meanwhile, a strategy of multi-model probabilistic voting model was proposed to reduce the influence from noise data on the classification. The proposed method was evaluated on Microsoft Research Action 3D dataset and Depth-included Human Action (DHA) database. The results indicate that the method has high accuracy and good robustness.
Key words:depth imageskeleton dataaction recognitiondepth motion mapQuadruples skeletal feature (Quad)
0 引言
行为识别是计算机视觉与模式匹配中的一个热门问题, 每天人们都会遇到许多潜在的人机交互。尽管这些年许多学者对行为识别做了许多卓越的贡献, 识别人类行为仍然是一个巨大的挑战。
早期的行为识别主要对视频进行处理。随着图像技术与硬件的发展, 利用微软Kinect或华硕Xtion等设备, 学者可以实时获取人体的深度图像信息。与传统的图像相比, 深度图像不受光照影响, 能够提供三维空间信息。利用深度图像, 学者们对行为识别做了许多研究, 例如文献[1-3];同时, 深度摄像头设备通过对深度数据的处理, 提取出了人体的骨骼特征[4], 为行为识别提供的重要的行为特征。
本文提出一种基于深度运动图数据与骨骼数据的融合识别方法。通过深度摄像头(RGB-Depth, RGBD)可以获取一个行为的一系列深度图像。将这一系列的深度图在3个视图方向(前视图、左视图、俯视图)上投影获取深度运动图, 并对得到的深度运动图进行局部二值模式(Local Binary Pattern, LBP)预处理, 只获取其纹理信息;同时对骨骼数据进行四方形坐标标定,利用Fisher对得到的骨骼数据进行预处理;最后将得到的深度运动图与骨骼特征输入到一个基于支持向量机(Support Vector Machine, SVM)的多模型概率投票的分类器中。本文在行为识别方面有2点贡献:1) 将深度图像信息与骨骼信息结合作为行为的数据特征;2) 提出了基于SVM的多模型概率投票机制, 很大程度上克服了噪声数据对模型的影响, 提高了识别率, 具有一定的鲁棒性。
对于传统的彩色摄像头采集的图像, 学者们大多利用其时空特征与轨迹进行行为识别:文献[5]利用时空点与SVM配合识别人体行为;文献[6]利用尺度不变的轨迹作为特征, 在3层的抽象等级上识别行为;文献[7]提出了在视频序列中提取运动能量图(Motion Energy Image, MEI)和运动历史图(Motion History Image, MHI)作为行为特征。使用图像强图或者颜色的一个主要缺点使其对光照变化敏感, 限制了算法的鲁棒性。蔡加欣等[8]对人体轮廓进行研究, 基于随机森林方法, 提出基于袋外数据误差加权投票准则的行为视频分类方法。
随着RGBD摄像头的发展, 学者们已经提出许多基于深度图像的行为识别算法:文献[9]利用金字塔模型与3D点的词袋模型作为行为姿态的行为特征; 文献[10]将深度图像投影到3个正交的平面上形成深度运动图(Depth Motion Map, DMM), 然后用提取其梯度直方图(Histogram Of Gradient, HOG)作为行为的特征; 文献[11]从深度视频中提取随机占用模式(Random Occupancy Pattern, ROP)特征, 并用稀疏编码技术进行重新编码; 郑胤等[12]介绍了深度学习及其目标和行为识别中的新进展。
随着对深度图像进一步的处理, 学者们提取出其中高层次的骨骼信息, 基于骨骼信息的算法可以更加直接地描述人体行为:文献[1]将人体定位到3D空间箱子模型, 提取人体的3D骨骼点直方图(Histogram Of 3D Joint, HOJ3D)作为行为特征; 文献[13]提出从人体骨骼节点的拓扑结构中选取最有子集来提高识别率; 文献[14]提出了一种生物启发的三维骨骼特征的时空层次结构; 文献[2]使用朴素贝叶斯近邻分类器识别人体骨骼特征点的静态与动态信息。
与传统单一的特征数据模型相比, 多特征有着良好的优势。文献[15]提出了跨数据模型的融合实验, 在IXMAS(INRIA Xmas Motion Acquisition Sequences)等数据库做了实验。在大数据环境下, 多特征协同识别成为人体行为识别趋势。结合深度图像与骨骼数据, 可以提高识别的准确性。
1 运动特征描述1.1 深度运动图特征
深度图像可以用来表示物体3D结构和形状信息。文献[10]提出将深度图像时间序列中的每一帧投影到正交的3个笛卡尔面来表示这个行为动作。具体地说, 使用三视图中的主视图、俯视图和左视图, 将人体定位到笛卡尔坐标系, 分别将人体深度数据投影到主视图、俯视图和左视图。每一帧行为可以表示为v={f,s,t}, 其中:f、s、t分别表示在主视图、左视图和俯视图的人体投影。与文献[2]不同, 每个投影的图是由2个连续的深度图像帧做差投影得到。对于N帧的深度数据视频, 由式(1)计算出它的DMMv特征:
DMMv=∑i=ab|mapvi−mapvi−1|(1)



























其中:i表示时间序列帧;mapvi表示在第i帧下的、在视图v上的投影;a和b分别表示开始帧和结束帧。
但是并不是所有深度图中的像素都需要被投影, 深度图像中很多像素值为0, 对行为特征描述没有帮助。所以要对每一帧图像进行感兴趣区域(Region Of Interest, ROI)操作。即裁剪图像, 使主要内容平铺在整个图像上, 且保证图像大小一致。为了进一步对DMMv中的像素进行过滤, 对DMMv进行局部二值模式(LBP)操作。LBP是一种用来描述图像局部纹理特征的算法, 可以提取DMMv中的纹理信息, 增加了特征的稀疏性。如图 1, 对于在图像上个给定的一点gc, 式(2)为LBP的计算公式:
LBPm,r(gc)=∑i=1mU(gi−gc)2i(2)


























图 1{gi}i=18示意图(r=1)

其中:U(x)={1,x⩾00,x<0;m为采样点个数,U(x)为判别函数。具体过程为:若gc的坐标是(xc,yc), 其半径为r的m个近邻采样点。
















{gi}i=1m的坐标可以表示为:






















(xc−rsin(2πi/m),yc+rcos(2πi/m))









经过式(2)计算出gc的m位的LBP编码作为gc的新数值, 那么图像就变为如图 2(d), 统计得到图像的直方图hv。
图 2深度运动图特征形成过程

以侧踢为例子, 如图 2,图 2(a)表示一个侧踢运动的深度图像序列。DMMf的大小为mf×nf,DMMs的大小为ms×ns,DMMt的大小为mt×nt。因为是用像素值作为特征, 为了避免大像素值对模型的影响, 将DMMv归一化到[0, 1], 同时进行ROI, 保证图像大小一致, 表示为DMMv¯, 则踢腿特征可以表示为h=LBP(DMMv¯),h的大小为(mf′×nf′+ms′×ns′+mt′×nt′)×1。








































1.2 骨骼特征(Quad)
由于微软的Kinect提供的骨骼数据带来的便利, 可以直接获取人体的20个骨骼节点。根据文献[16]所提出的四方形骨骼表示法对骨骼点进行处理, 如图 3所示。x∈R3表示在真实世界坐标系下人的骨骼点坐标。则X=[X1,X2,X3,X4]。X1与X2为相距较远的点。以X1作为原点,X2映射到[1, 1, 1]T, 构建本地坐标系。当这2个点确定后, 剩下的2个点则可以用如下公式计算出:
S(xi)=sR[xi−x1](3)















图 3四方形骨骼表示

其中:s表示缩放矩阵,R表示旋转矩阵。令S(X1)=[0, 0, 0]T,S(X2)=[1, 1, 1]T, 则当前4个骨骼点特征可表示为q=[S(X3);S(X4)], 其大小为6×1, 如图 3。
取图 3(a)左臂4个节点作为一个四方形骨骼表示点。相距较远的2个点分别作为(0, 0, 0)和(1, 1, 1), 则该4点的特征表示为q=[x3,y3,z3,x4,y4,z4]T。
由于能检测到的人体关节见有20个, 即存在的四方形骨骼特征有C204=4 845个。对于一个k帧的行为动作, 特征可表示为:
















Q={qji|i∈(1,C204)|,j∈(1,k)}(4)













由于Q的大小与k有关, 而每个动作的k又不同, 导致每个行为的骨骼特征大小不同。为了避免这个问题, 对Q进行Fisher处理。由文献[17]可知, 利用高斯混合模型的Fisher, 可以将Q转换为Fisher向量F。F的大小为2fd×1。f在本文高斯混合模型中取128,d为Q的行数量, 在本文为6, 即F的大小为1 536×1。
2 基于SVM的概率投票行为识别
单个的SVM只能解决二分类问题, 对于多分类的问题, 可以使用多个SVM分类器联合分类, 包括一对一、一对多等方法。虽然直接分类的SVM是一个强有力的机器学习的分类工具, 然而在实际应用中, 由于噪声的影响, 每个样本对分类结果的影响应该是不同的。直接将结果分类成0和1可能并不恰当。为了使SVM更加适应这些问题, 要求SVM具有软输出的功能, 即输出概率。本文的SVM概率投票分类就是基于输出概率进行的。
给定的行为识别特征数据包括深度运动图特征与四方形骨骼特征。其中深度运动图特征包括v={f,s,t}三个方向的特征。对于三个方向的深度运动图特征与骨骼特征, 对各个特征进行SVM概率建模, 将得到的模型进行累加投票, 得到最大目标可能概率, 即为最后输出标签。


















Label=max(∑ModelSVM(E));E∈{v,F}(5)













v代表前视图、左视图与俯视图三个方向。F代表骨骼数据在Fisher操作后的骨骼特征。如图 4, 对于每个特征进行SVM分类, 得到各个特征的模型。与以往的SVM不同, 该训练的几个模型输出均为识别概率。将概率累加, 获取最大概率的标签即为结果。
图 4SVM二分类
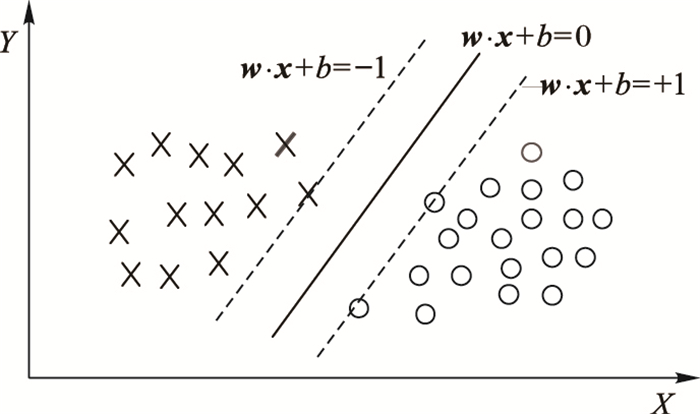
SVM是机器学习中的强有力的学习方法。传统的SVM是解决单分类问题。SVM试图找出一个超平面, 使超平面能够尽量多地分隔出两类。经过大量实验证明, SVM在小样本集上有着卓越的优势。
如图 4所示。SVM希望在这两类中找出一个平面。如式(6),f(x)大于0对应y=1,f(x)小于0对应y=-1。
f(x)=w⋅x+b(6)










为了SVM能够进行概率输出, 使用挤压函数sigmod将f(x)映射到[0, 1], 如式(7):















p(y=1|f)=1/1+exp(Af+B)(7)







为了保证公式的单调性, 设置A< 0。通过这样, 可以输出带概率的SVM分类结果。
对于多分类的概率支持向量机(Probability Support Vector Machine, PSVM), 对每个带概率的SVM进行一对一, 该方法在每两类训练一个分类器, 因此对于一个k类问题, 将有k(k-1)/2个分类函数。当对一个未知样本进行分类时, 每个分类器都对其类别进行判断.并为相应的类别“投上一票”, 最后得票最多的类别即作为该未知样本的类别。决策阶段采用投票法, 传统的投票法可能存在多个类的票数相同的情况, 从而使未知样本同时属于多个类别, 影响分类精度, 基于概率输出的投票法可以避免这方面的问题, 取得更好的效果。
由于是多特征的概率SVM投票模型, 那么需要对每个模型进行SVM参数调优, 在每个单独模型上, 调整SVM的准确度到最优。
与以往的SVM不同, 该训练的几个模型输出均为识别概率。将概率累加, 获取最大概率的标签即为结果。这样有如下优点:
1) 对不同特征进行不同的处理, 发挥特征的最好效果。
2) 可以集成当前效果最好的特征进行分类, 极容易拓展。
3) 随着计算机性能的提高, 概率投票方式不会受到计算机性能的约束, 可以达到实时的效果。
3 实验结果与分析3.1 MSR-Action3D实验3.1.1 实验数据
MSR-Action3D数据库是一个关于Kinect采集数据的行为识别库, 其中包括10个人做20个动作: high wave(HiW)、horizontal wave(How)、hammer(H)、hand catch(HC)、forward punch(FP)、high throw(HT)、draw x(DX)、draw tick(DT)、draw circle(DC)、hand clap(HC)、two hand wave(THW)、side boxing(SB)、bend(B)、forward kick(FK)、side kick(SK)、jogging(JO)、tennis swing(TS)、tennis serve(TS)、golf swing(GS)、pickup throw(PT)。每个人做2~3次。总共包括557个240×320的深度图像与557个骨骼数据。
图 5行为识别算法流程
3.1.2 实验设置
设置一 与文献[3]中的设置相同, 将20个行为分为3组(AS1、AS2、AS3), 如表 1, AS1与AS2里都是相似行为, 而AS3里则是相似度较小的行为。对每一组进行3个实验。在实验一中, 1/3作为训练数据, 2/3作为测试数据。实验二中, 2/3作为训练数据, 1/3作为测试数据。实验三中一半数据作训练, 剩余一半作测试。
表 1MSR-Action3D数据分组

设置二 与文献[11]中设置相同, 同时使用20个行为, 一半作为训练数据, 剩余一半作为测试数据。因为需要识别的类别比较多, 设置二更具有挑战性。
3.1.3 实验结果与分析
实验主要分为三个方面:单一特征实验、特征融合实验与稳定性实验。对深度运动图特征、四方形骨骼特征和两者的结合分别进行设置二的实验, 验证特征融合的必要性。同时将本算法与现有的其他算法进行对比。最后, 对实验数据进行随机抽样, 测试算法的稳定性。
单一特征实验 对深度运动图、四方形骨骼特征和两者的融合分别进行实验。根据设置二的数据安排, 一半数据作为训练, 一半数据作为测试, 一共20类行为。比较在设置二下的各种情况的识别率。如表 2所示, 将深度运动图与四方形骨骼特征融合, 有着更高的识别率。
表 2单一特征实验结果

特征融合实验根据实验设置一进行实验, 与现有的方法进行对比, 结果如表 3, 可以看出, 本文的方法在实验一(1/3为训练样本, 2/3为测试样本)的识别率比现有的方法识别率低, 对于小样本的识别率不高。在实验二(2/3作为训练样本, 1/3作为测试样本)中, 本文的识别率已经与现有的方法大体持平, 在AS3子集中更是达到了100%。而在实验三(1/2作为训练样本, 包括1、3、5、6、7、9号人的行为数据, 剩余作为测试样本)中, 本文的识别率明显高于现有的方法。文献[2]与本文方法的混淆矩阵如图 6所示。在表 3的实验三中, 其具体分类准确率的混淆矩阵如图 6所示。在AS1与AS2这2个相似动作的数据子集中, 本文的方法降低了错分率, 提高了准确率。在AS3中, 本文方法对许多动作能够完全地区分开来, 准确率达到100%。
图 6文献[2]方法与本文方法混淆矩阵对比
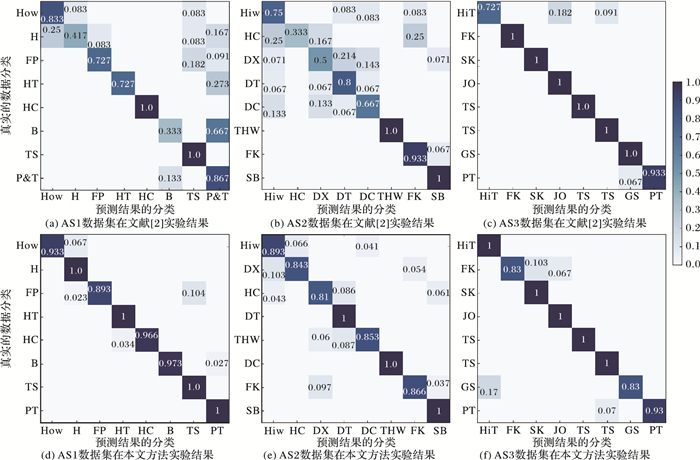
表 3设置一实验结果%

根据实验设置二进行实验, 与现有方法对比, 结果如表 4。因为实验设置二将所有20类行为一起进行训练识别, 实验设置二对于算法的识别率更具有挑战。根据结果可以看出, 本文方法有着较高的识别率, 达到91.3%, 仅次于文献[18]。
表 4设置二实验结果

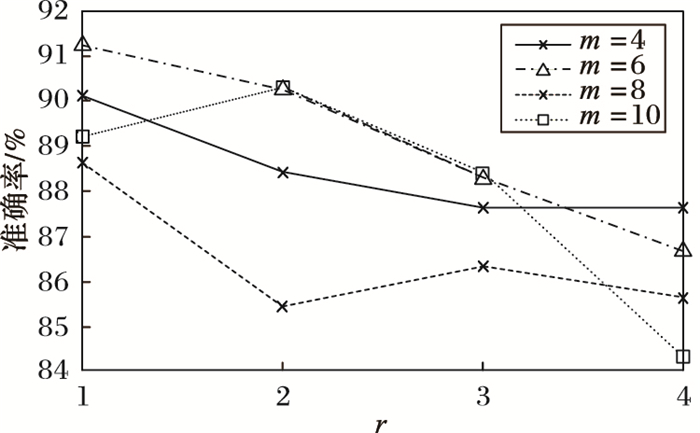
在深度运动图预处理中, 由于对投影后的深度图进行了LBP处理, 即不同LBP参数m与r对结果有着直接的影响。如图 7所示, 随着r的变大, 即放大LBP的尺度, 降低了边缘提取的效果, 准确率总体呈下降趋势。同时, 随着m取值变化, 识别率上下波动, 实验选择了4个m的选值, 由图 7可知, 当m为6、r为1时, 本文算法有着较高的识别率。
图 7不同r与m的准确率(设置二)
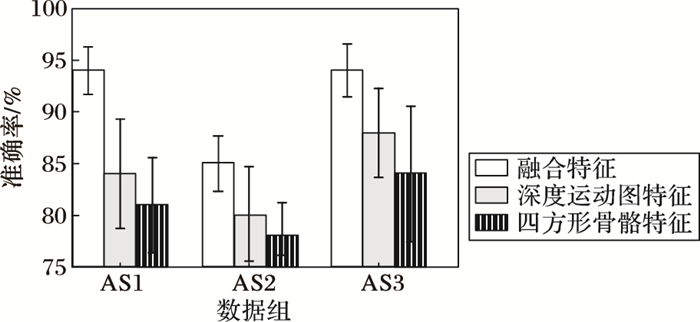
稳定性实验 为了测试融合特征的稳定性, 在设置一的基础上, 对于深度运动图特征、四方形骨骼特征和两者结合特征分别进行随机抽样实验, 如图 8所示。特征融合后, 识别率有很大的提高, 同时, 在随机抽样测试下, 识别率的稳定性也有所提高, 增强了系统的稳定性。
图 8稳定性测试
3.2 DHA实验数据3.2.1 实验数据
DHA(Depth-included Human Action)深度数据库包括了23类人体行为, 分别是:bend、jack、jump、pjump、run、side、skip、walk、one-hand-wave、two-hand-wave、front-clap、side-clap、arm-swing、arm-curl、leg-kick、leg-curl、rod-swing、golf-swing、front-box、side-box、tai-chi、pitch、kick。DHA数据集包括了深度数据和彩色数据。深度数据图像和彩色数据图像大小都是480×640。该数据集的深度图像已经作了预处理, 将背景去除, 把人体深度数据分割出来。DHA数据集由21个人录制, 每个人每种动作做一次, 数据集总共是483个视频序列。如图 9展示了DHA数据集的深度图像。
图 9DHA数据集深度图

3.2.2 实验设置
本实验使用留一法进行数据准备。数据集一共有21个人, 则将数据集分成21份。然后依次随机从中间抽取一份做测试样本, 其余的20份作为训练样本。反复这个操作10次, 则有10份随机的测试样本和与之对应的各个20份的训练样本。最后在得到的10次实验结果取其平均值,这样做可以有效避免由于样本原因导致的实验的巧合性。
3.2.3 实验结果与分析
同样, 实验分为3个方面:运动过程单一特征与多特征融合实验、运动过程与特征处理融合实验和概率投票实验。对于DHA数据库, 由于只有深度图像数据, 经过Kinect的SDK(Soft Develop Toolkit), 转换出对应的骨骼数据进行算法识别。
1) 运动过程单一特征与多特征融合实验。
对于单一的特征, 在DHA实验数据上的结果如表 5所示。对于单一的特性, 在DHA数据集上, 运动历史图(Motion History Image, MHI)的准确率比DMM的高, Quad相对低一点。在MHI、DMM与Quad的结合实验中, 本文方法仍然比其他单一的准确率高。
表 5单一性比较

2) 运动过程与特征处理融合实验。
在DHA数据集上, 采用相同的方法进行实验比较, 如表 6所示, 在DHA上DMM的准确率仍然比MHI高。同时等价模式局部二值模式(Uniform Pattern Local Binary Pattern, UPLBP)比单一的LBP、HOG与金字塔方向梯度直方图(Pyramid Histogram of Oriented Gradient, PHOG)效果好。
表 6融合实验

表 7所示, PSVM的准确率比单一SVM的准确率高。
表 7概率投票实验

实验证明, DMM-PSVM仍然表现良好。接下来比较特征处理。如表 8所示, 在特征处理方面, UPLBP效果比HOG和PHOG效果好。
表 8几种方法特征比较

将深度图像与骨骼数据相结合, 与单一的深度图像进行比较, 结果如表 9。结果表明, 深度图像与骨骼图像相结合, 能提高算法的准确度。
表 9深度与骨骼实验

3.3 时间复杂度分析
由于是多特征融合, 所以时间复杂度会相对较高。在深度图像方面, DMM的每个方向的时间复杂度为O(n), 经过LBP特征处理后, 时间复杂度增加到O(n3)。在骨骼点方面, Qaud的时间复杂度为O(n), 然而对Quad进行Fisher编码, 其时间复杂度变为O(n2)。将深度图像与骨骼数据放入基于概率输出的SVM, 其各自的SVM的时间复杂度为O(n3), 经过多特征融合, 最后整个算法的时间复杂度为O(n3)。
4 结语
本文提出了一种深度图像数据与骨骼数据结合的方案, 将深度运动图与骨骼四方形特征同时作为识别人体行为的特征; 同时提出了多模型概率投票的分类策略, 克服了噪声对单个模型的影响, 具有较好的鲁棒性。以后的工作考虑更多的数据特征协同表示, 同时降低算法的复杂度, 增强算法的实时性。
参考文献
[1]XIA L, CHEN C C, AGGARWAL J K. View invariant human action recognition using histograms of 3D joints[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ:IEEE, 2012:20-27.http://www.oalib.com/references/16436168
[2]YANG X, TIAN Y. Eigen-joints-based action recognition using naive-Bayes-nearest-neighbor[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ:IEEE, 2012:14-19.
[3]LI W, ZHANG Z, LIU Z. Action recognition based on a bag of 3D points[C]//Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ:IEEE, 2010:9-14.http://www.oalib.com/references/16436180
[4]SHOTTON J, FITZGIBBON A, COOK M, et al. Real-time human pose recognition in parts from single depth images[C]//Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ:IEEE, 2011:1297-1304.http://www.oalib.com/references/16425378
[5]SCHULDT C, LAPTEV I, CAPUTO B. Recognizing human actions:a local SVM approach[C]//Proceedings of the 17th IEEE International Conference on Pattern Recognition. Piscataway, NJ:IEEE, 2004, 3:32-36.
[6]SUN J, WU X, YAN S, et al. Hierarchical spatio-temporal context modeling for action recognition[C]//Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ:IEEE, 2009:2004-2011.http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5206721
[7]BOBICK A, DAVIS J. The recognition of human movement using temporal templates[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(3): 257-267.doi: 10.1109/34.910878
[8]蔡加欣, 冯国灿. 基于局部轮廓和随机森林的人体行为识别[J]. 光学学报, 2014, 34(10): 204-213. (CAI J X, FENG G C. Action recognition based on local contour and random forest[J].Acta Optica Sinica, 2014, 34(10): 204-213.)
[9]LI W, ZHANG Z, LIU Z. Action recognition based on a bag of 3D points[C]//Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ:IEEE, 2010:9-14.http://www.oalib.com/references/16436180
[10]YANG X, ZHANG C, TIAN Y. Recognizing actions using depth motion maps-based histograms of oriented gradients[C]//Proceedings of the 20th ACM International Conference on Multimedia. New York:ACM, 2012:1057-1060.http://cn.bing.com/academic/profile?id=2008824967&encoded=0&v=paper_preview&mkt=zh-cn
[11]WANG J, LIU Z, CHOROWSKI J, et al. Robust 3D action recognition with random occupancy patterns[C]//Proceedings of the 12th European Conference on Computer Vision. Berlin:Springer-Verlag, 2012:872-885.
[12]郑胤, 陈权崎, 章毓晋. 深度学习及其在目标和行为识别中的新进展[J]. 中国图象图形学报, 2014, 19(2): 175-184. (ZHENG Y, CHEN Q Q, ZHANG Y J. The new development of deep learning in action recognition[J].Journal of Image and Graphics, 2014, 19(2): 175-184.)
[13]CHAARAOUI A A, PADILLA-L'OPEZ J R, CLIMENT-P'EREZ P, et al. Evolutionary joint selection to improve human action recognition with RGB-D devices[J]. Expert Systems with Applications, 2014, 41(3): 786-794.doi: 10.1016/j.eswa.2013.08.009
[14]CHAUDHRY R, OFLI F, KURILLO G, et al. Bio-inspired dynamic 3D discriminative skeletal features for human action recognition[C]//Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Washington, DC:IEEE Computer Society, 2013:471-478.http://www.cv-foundation.org/openaccess/content_cvpr_workshops_2013/W12/html/Chaudhry_Bio-inspired_Dynamic_3D_2013_CVPR_paper.html
[15]LIN Y Y. Depth and skeleton associated action recognition without online accessible RGB-D cameras[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ:IEEE, 2014:2617-2624.http://www.cv-foundation.org/openaccess/content_cvpr_2014/html/Lin_Depth_and_Skeleton_2014_CVPR_paper.html
[16]VIEIRA A W, NASCIMENTO E, OLIVEIRA G. STOP:space-time occupancy patterns for 3D action recognition from depth map sequences[C]//Proceedings of the 17th Iberoamerican Congress on Pattern Recognition. Berlin:Springer-Verlag, 2012:252-259.http://link.springer.com/chapter/10.1007/978-3-642-33275-3_31
[17]GEORAIOS E, GURKIRT S, RADU H. Skeletal quads:human action recognition using joint quadruples[C]//Proceedings of the 201422nd International Conference on Pattern Recognition. Piscataway, NJ:IEEE, 2014:4513-4518.https://hal.archives-ouvertes.fr/hal-00989725/
[18]XIA L, AGGARWAL J. Spatio-temporal depth cuboid similarity feature for activity recognition using depth camera[C]//Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ:IEEE, 2013:2834-2841.http://www.cv-foundation.org/openaccess/content_cvpr_2013/html/Xia_Spatio-temporal_Depth_Cuboid_2013_CVPR_paper.html
[19]OREIFEI O, LIU Z. HON4D:histogram of oriented 4D normals for activity recognition from depth sequences[C]//Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ:IEEE, 2013:716-723.
[20]WANG J, LIU Z, WU Y. Mining actionlet ensemble for action recognition with depth cameras[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ:IEEE, 2012:1290-1297.http://www.oalib.com/references/16436170
[21]TRAN Q D, LY N Q. Sparse spatio-temporal representation of joint shape-motion cues for human action recognition in depth sequences[C]//Proceedings of the 2013 IEEE RIVF International Conference on Computing and Communication Technologies. Research, Innovation, and Vision for the Future. Piscataway, NJ:IEEE, 2013:253-258.http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6719903
[22]RAHMANI H, MAHMOOD A, HUYNH D Q, et al. Real time action recognition using histograms of depth gradients and random decision forests[C]//Proceedings of the 2014 IEEE Winter Conference on Applications of Computer Vision. Piscataway, NJ:IEEE, 2014:626-633.
[23]VEMULAPALLI R, ARRATE F, CHELLAPPA R. Human action recognition by representing 3D human skeletons as points in a lie group[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ:IEEE, 2014:588-595.http://www.cv-foundation.org/openaccess/content_cvpr_2014/html/Vemulapalli_Human_Action_Recognition_2014_CVPR_paper.html
[24]CHEN C, LIU K, KEHTARNAVAZ N. Real-time human action recognition based on depth motion maps[J].Journal of Real-Time Image Processing, 2013, 12 (1) : 155-163.
