1.简介
- 正则表达式,是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种匹配逻辑。从而实现以匹配逻辑为核心的一系列搜索、提取、替换等功能。
- 正则表达式已经被广泛地应用在编程语言、编辑器、指令脚本当中,是工作中的一把利器。
-
先来系统地看一下正则表达式的语法(只列举了笔者认为常用的部分):
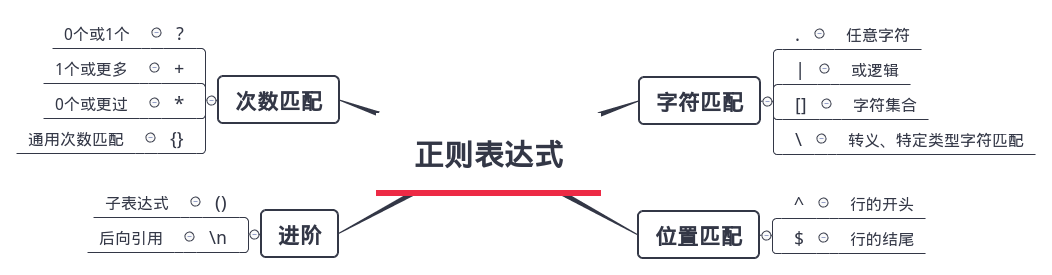 正则表达式.png-31.4kB
正则表达式.png-31.4kB
暂时对正则表达式使用没有概念也没关系,后面会有详细说明,这里先有一个大概的了解即可。
- 学习正则表达式时,有一个方便的正则语法验证工具非常重要。这里推荐https://regexper.com,它除了可以检查正则的语法,还能将我们的正则逻辑用图形化的方式表达出来。比如对用一个邮箱正则
^[\w-]+@[\w-]+(\.[\w-]+)+$,图示如下:
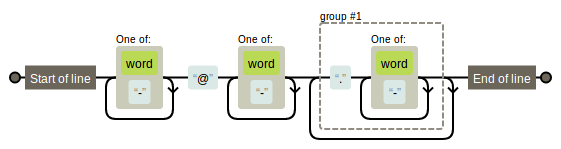 email.png-8kB
email.png-8kB
2.基础
在基础部分,将为大家介绍如何使用字符匹配、位置匹配和次数匹配:
1.字符匹配
- 匹配任意字符 “.”
- 例如
a.c的图示为:
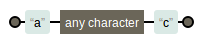 img.png-1.8kB
img.png-1.8kB - 也可以多个点连用,比如
a..c:
 img.png-2kB
img.png-2kB
当然,使用次数匹配(下文详细介绍)也可以达到相同的效果,a.{2}c:
 img.png-2.7kB
img.png-2.7kB
- 或逻辑 “|”
- “|”默认会将两边所有的字符作为参数。例如
1a|b3:
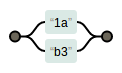 img.png-1.9kB
img.png-1.9kB
如果想指定参数范围必须使用子表达式(下文详细介绍)1(a|b)3:
3.png) img.png-3.3kB
img.png-3.3kB
- 字符集合 “[]”
- “[]”可以匹配几个特定字符中的一个。例如
1[abc]3:
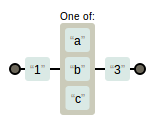 img.png-2.5kB
img.png-2.5kB - “[]”也可以作用在字符组区间上。例如
1[a-c]3:
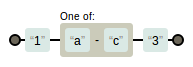 img.png-2.1kB
img.png-2.1kB
类似的,[a-z]表示字母a到z之间的任意一个字母,[0-9]表示0到9之间的任意一个数字。 - “[]”和“^”搭配,可以表示非字符集的匹配。例如
1[^a-c]3:
 img.png-2.1kB
img.png-2.1kB
即,把^放在[]里最前面的位置,表示任意一个非[]中字符的字符。
- 转义、特定类型字符 “\”
- “\”在很多编程语言代表转义字符,在正则表达式中也是一样的。比如“.”是一个元字符(正则表达式中代表特殊含义的字符),表示任意一个字符。那如果想要表示“.”本身的含义,就需要写成“\.”。例如
a\.c专指匹配“a点c”这三个字符的字符串:
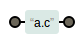 img.png-0.9kB
img.png-0.9kB - “\”在正则表达式中除了代表转义,还可以与其他字母组合,表示指定类型字符。例如“\d”表示任何数字,
a\dc:
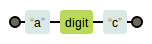 img.png-1.4kB
img.png-1.4kB
将字母大写,表示“非”的意思,例如任意一个非数字的字符,可以用“\D”表示,a\Dc:
 img.png-1.7kB
img.png-1.7kB
类似的有:
| 元字符 | 描述 |
|---|---|
| \d | 任何数字 (同 [0-9]) |
| \D | 任何非数字 (同 [^0-9]) |
| \w | 所有的文字数字式字符:大小写字母、数字和下划线 (同 [a-zA-Z0-9_]) |
| \W | (同 [^a-zA-Z0-9_]) |
| \s | 所有的空白字符 (同 [\f\n\r\t\v]) |
| \S | 所有的非空白字符 (同 [^\f\n\r\t\v]) |
2.位置匹配
- 行边界匹配的元字符是“^”和“
`:
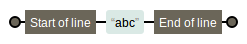 img.png-2.2kB
img.png-2.2kB
3.次数匹配
- 出现0个或1个 “?”
- “?”表示一个字符可以不出现,或只出现一次。例如
ab?c:
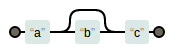 img.png-1.6kB
img.png-1.6kB - 需要注意的是,“?”是贪婪匹配的(即优先匹配字符出现次数多情况)。例如下面的Java代码:
Pattern p=Pattern.compile("ab?");
Matcher m=p.matcher("ab111");
System.out.println("m.find(): " + m.find());
System.out.println("m.group(): " + m.group());
// 输出
m.find(): true
m.group(): ab
- 但是“?”表示出现0个或1个,也就是说在上面的代码中,对于“ab111”来说,“a”字符串也应该是“ab?”表达式下的匹配项。那如果才能匹配到“a”呢?这就需要用到“?”元字符的另一个含义了:懒匹配(即优先匹配字符出现次数少的情况)。
- 也就是说,“?”这个元字符比较特殊,它有两个含义,除了在次数匹配中表示出现0个或1个外,在匹配模式上,它表示使用懒模式。
- 所以上面Java代码的例子中,如果想要匹配到“a”这个字符串,需要将表达式改为“ab??”:
Pattern p = Pattern.compile("ab??");
Matcher m = p.matcher("ab111");
System.out.println("m.find(): " + m.find());
System.out.println("m.group(): " + m.group());
// 输出
m.find(): true
m.group(): a
- 出现1个或更多 “+”
- “+”表示一个字符至少出现一次。例如
ab+c:
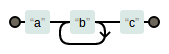 img.png-1.6kB
img.png-1.6kB - 与表示0个或1个的“?”相同,"+"默认也是贪婪模式,如果想要懒模式,则要使用“+?”:
Pattern p = Pattern.compile("\\d+");
Matcher m = p.matcher("aaa2223bb");
System.out.println("m.find(): " + m.find());
System.out.println("m.group(): " + m.group());
p =Pattern.compile("\\d+?");
m = p.matcher("aaa2223bb");
System.out.println("m.find(): " + m.find());
System.out.println("m.group(): " + m.group());
// 输出
m.find(): true
m.group(): 2223
m.find(): true
m.group(): 2
- 出现0个或更多 “*”
-
"*"表示一个字符可以出现任意次。例如
ab*c:
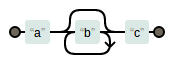 img.png-1.9kB
img.png-1.9kB "*"也是贪婪模式的,用“*?”表示懒模式:
Pattern p = Pattern.compile("\\d*");
Matcher m = p.matcher("2223");
System.out.println("m.find(): " + m.find());
System.out.println("m.group(): " + m.group());
p =Pattern.compile("\\d*?");
m = p.matcher("aaa2223bb");
System.out.println("m.find(): " + m.find());
System.out.println("m.group(): " + m.group());
// 输出
m.find(): true
m.group(): 2223
m.find(): true
m.group():
- 通用次数匹配 “{}”
- “{}”是次数匹配当中最灵活通用的,它的用法如下:
| 表达式 | 描述 |
|---|---|
| {3} | 精确次数匹配,表示一个字符连续有3个 |
| {3,} | 至少次数匹配,表示一个字符至少连续有3个 |
| {3,5} | 区间次数匹配,表示一个字符连续有3到5个 |
- 所以?和{0,1}的功能是一样的,+和{1,}的作用是一样的。
- 我们以区间次数匹配为例,看一下
ab{3,5}c的图示:
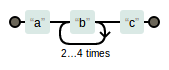 img.png-2.2kB
img.png-2.2kB
3.进阶
在进阶部分,将为大家介绍子表达式和后向引用:
1.子表达式
- 通过()括起来的就是子表达式。
- 为了说明子表达式的用途,先来看一个表示IPv4地址的表达式(为简单起见,不校验是否超过了256):
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3},图示为:
 ip.png-2.9kB
ip.png-2.9kB - 从上面的表达式我们可以看到
\d{1,3}\.重复了三遍,使用子表达式,可消除重复,表示为:(\d{1,3}\.){3}\d{1,3},图示为:
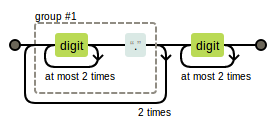 ip2.png-5kB
ip2.png-5kB - 除了消除重复,子表达式还有另外一个重要的作用,那就是明确范围。在之前将逻辑或“|”元字符的时候,曾经提过,“|”会把自己两边所有的字符都作为参数,如果只想要部分字符作为参数,则可以使用子表达式。看下面两个表达式的区别:
-
19|20\d{2}
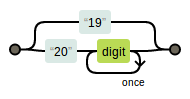 year1.png-3.1kB
year1.png-3.1kB -
(19|20)\d{2}
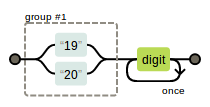 year2.png-4.4kB
year2.png-4.4kB
2.后向引用
- 后向引用就是将前面的子表达式理解成变量使用。例如\1匹配模式中第一个子表达式,\2匹配第二个子表达式,\3匹配第三个。
- 来看一个例子:
System.out.println(Pattern.compile("<H([1-6])>.*?</H\\1>").matcher("<H1>html_code</H1>").matches());
System.out.println(Pattern.compile("<H([1-6])>.*?</H\\1>").matcher("<H1>html_code</H2>").matches());
// 输出
true
false
- 上面的Java代码,用同一个表达式对两段html代码进行了匹配性检查。第一段html代码“<H1>html_code</H1>”检查通过;而第二段html代码“<H1>html_code</H2>”没有通过,原因就是后向引用“\1”要求必须和前面的子表达式“([1-6])”内容相同。因为他们代表的是同一个变量。
end
