细胞是构成生物体不可分割的基本组成单位。细胞通过细胞膜(细胞壁),划出了自己清晰的边界。在边界内部,细胞有自己的各种物质。而细胞膜则控制着允许外界通过的物质。
而class在OOP的地位,像细胞一样,构成了一个OO程序的基本组成单位,并具有不可分割性。一个类内部由多种元素组成。其中一部分元素,设计者是不希望外部能够访问的;因而类则必须具备细胞膜同样的性质:对包含的各种元素进行访问控制,由此定义明确而清晰的边界。这就是类的封装(encapsulation)。
封装的目的
一提起封装,程序员们首先想到的是对类成员的private,public控制。但这些都是手段。相对于手段,目的才更为重要。
应用OO的正确姿势,是将类当做一种模块化手段。而好的模块划分原则是高内聚,低耦合。(参见《正交设计,OO与SOLID》)因而,如果你不能很好的理解内聚与耦合,你就很难通过OO方法学得到好的设计(事实上,如果不懂内聚与耦合,你用任何方法学都无法针对一个复杂系统给出良好的设计)。
而高内聚强调的是:关联紧密的事物应该被放到一起。这样有助于将不稳定的、易于一起变化的元素都控制在一个模块内部。从而做到局部化影响。
而低耦合则强调:API的定义要让客户与之的耦合尽可能小,让客户代码难以受到变化影响。
而封装的目的正是为了隔离变化。通过对客户提供抽象接口,隐藏实现细节,让客户代码只能依赖于更稳定的抽象,与易于变化的实现细节进行隔离,从而让客户代码更加稳定(向着稳定方向依赖)。
如果不能做到这一点,你即便使用了再多的private权限控制,也无法改善软件的内部质量。
数据与算法
我们都知道,无论你采取何种范式,从宏观角度,程序最终都是由如下两部分构成:
- 数据
- 算法
可是,如果我们对于程序的理解仅仅停留在这个层面,那么就很难设计出易于应对变化的软件。
不幸的是,从我多年做咨询的经历来看,绝大部分系统的工程师和设计师,对于设计的理解都还限于这个层面,不管他们讲的多么天花乱坠,图画的有多漂亮,但最终的代码会揭开谎言,告诉你一切真相。
让我们看看,如果仅仅将程序看做数据和算法,并将它们清晰分离,系统会呈现的局面:
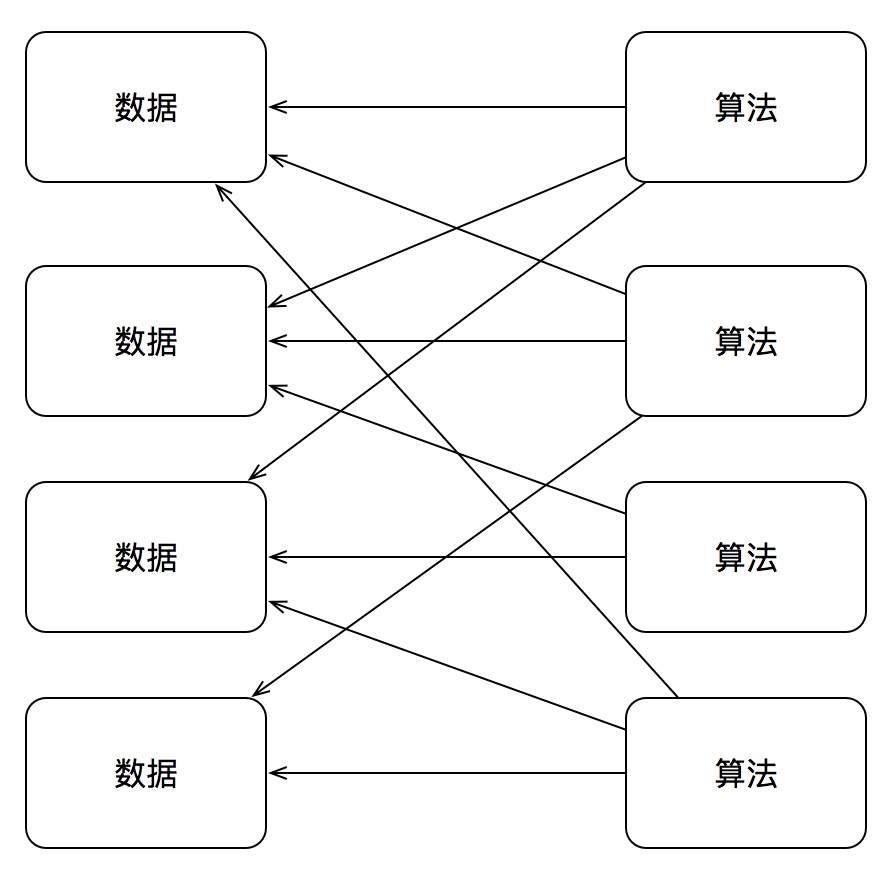
而具体到一个数据结构,需要访问数据的客户代码与其之间的依赖关系则如下:
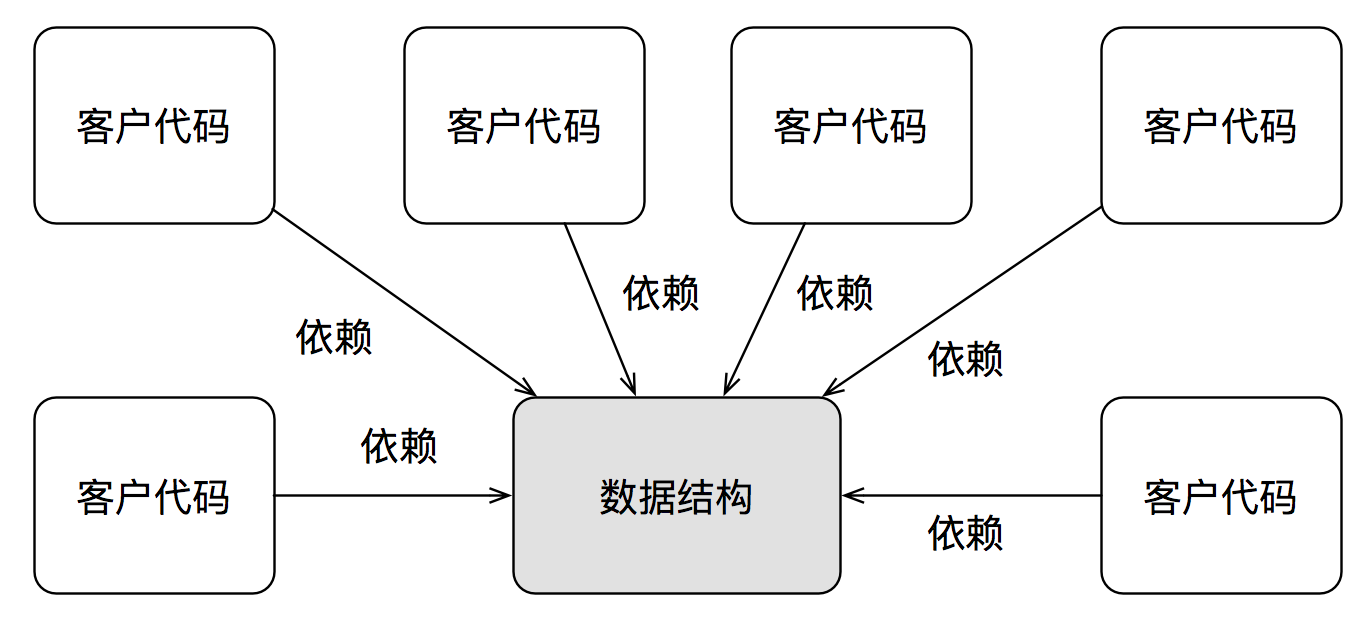
数据结构在很多时候,都是一种不稳定的实现细节,而客户代码对于不稳定实现细节的大面积依赖,会导致系统耦合度的急剧上升。从而让系统在变化面前极其脆弱。
而为了提升内聚度,降低耦合度,我们需要采取向着稳定方向依赖的策略,从而得到:
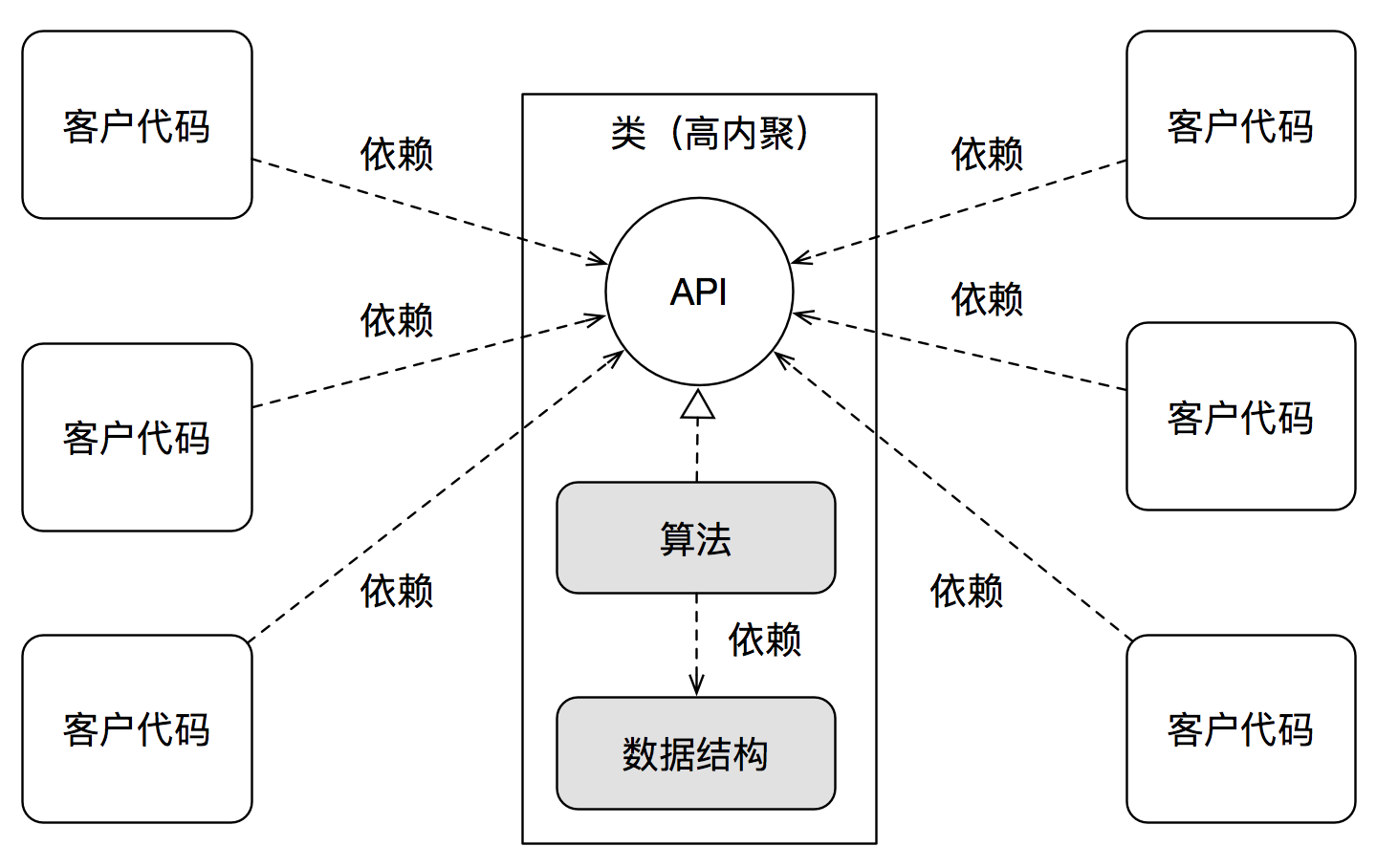
尽管依赖范围(数量)依然,但由于API是站在站在客户真正需要的角度定义的更为稳定的抽象接口(参见《我们该如何定义API》),其稳定度大大提升,从而降低了系统的耦合度。
更何况,很多时候,经过封装,甚至连依赖范围也会随之缩小。
TELL, DON'T ASK
Greg Willits在论文《OOP Principles in Action: Tell, Don't Ask》的开篇就解释了TDA的思想:
Tell, Don't Ask is a paradigm or style of object oriented programming which prefers that objectA tells objectB to do something, rather than asking ob- jectB about its state so that objectA can make a decision.
这种思想对于一直以面向过程方式思考的人是颠覆性的。
很多程序员,即便开始使用C++,Java等OO语言,也会很习惯的一上来就为每个数据成员都添加上Setter和Getter接口。
当然把数据全部都暴露出去,会让程序员在系统各处使用时非常便利。但这种贪图一时之爽的便利背后意味着对系统可维护性的长期危害。
这种做法是典型的数据+算法的程序设计思路,完全没有任何高内聚,低耦合的基本素养。对于这样的设计,OO不仅不会给你带来任何好处,反而增加了很多麻烦(更复杂的语法,类的原子不可分割性等等),这也是多年来OO在一部分圈子里承受恶名的重要原因之一。但这究竟是谁的错?
可是,这并非意味着所有的Getter都是邪恶的。封装的目的在于封装变化。如果本来某种信息的获取就是一种稳定的本质需要,而不是易于变化的实现细节,那么这种Getter就是合理的。
例如,每一个Entity对象,都有一个身份证号(Identity),通过它,可以从仓库(Repository)中对Entity进行查找,因而一个Entity暴露一个getId()的接口是非常合理的。比如:
struct FooEntity
{
unsigned int getId() const;
// ...
};
但同时,对于Id的表示却有必要进行封装,因为它很可能是个不稳定的实现细节,今天或许是一个32位整数,明天就会变为64位,后天干脆变成了一个128位的字符串(你要是觉得这也是稳定的,不妨想想我们身份证号的升位)。而当变化没有发生之前,你至少要先通过最简单的手段将这个信息进行封装(隐藏),比如:
typedef unsigned int FooId;
struct FooEntity
{
FooId getId() const;
// ...
};
这样的做法,考虑其投入的成本,可获得的收益,绝不属于过度设计。
最后,即便回到最坏的局面,Getter还是会比直接暴露数据略胜一筹。毕竟,Getter是个函数,而函数比数据更具备弹性。
避免重复
众所周知,重复是软件可维护性问题的主要原因之一。
在一些以C语言为主开发的大系统中,类型的重复定义,同一算法的重复实现是一个非常普遍的现象。这种重复很多时候并非故意为之,而是在缺乏封装的情况下,必然导致的结果。
比如,在如下代码中,结构体Rectangle被传递给不同的函数, 而每个函数都有基于Rectangle的计算。
struct Rectangle
{
int width;
int height;
};
// 模块的外部接口,rect 由其它模块传入
void f1(Rectangle* rect){
int area = rect->width * rect->height;
// ...
}
void f2(Rectangle* rect)
{
int perimeter = 2 * (rect->width + rect->height);
// ...
}
void f3(Rectangle* rect)
{
// 和 f1 一样的计算
int area = rect->width * rect->height;
// ...
}
从中,我们能够看到f1 和 f3 有着相同的计算。而类似于这样的重复,在大型系统中非常普遍。
我们可以站在一个开发者的角度,来思考为何会产生这样的结果。
由于C的结构体是不能有行为的,那么结构体的所定义的数据和操作它们的数据行为就是分离的 (缺乏内聚性)。那么对一个开发者而言,既然他可以轻松拿到所需数据,他所需要的计算就可以亲自完成;至于别人是否已经实现过类似的代码,他并不知道。难道要让他去庞大的代码库中四处搜索?这还不如自己亲自写更方便一些。
其造成的结果必然是:相同的算法就被多个开发者重复实现。只有极其有心的开发者才可能会尽力的降低一些这类的重复。当然,这是以付出额外精力为代价的。
但一旦把这些行为都放在类中,把数据隐藏起来,就可以最大程度的避免重复。
首先开发者们失去了自由访问数据的权力。如果一个开发者需要某种计算,数据访问权的丧失会让他首先考虑的不是在类的外部亲自实现某个算法,而是首先寻求复用别人的实现。
那别人是否曾经实现过呢?无须到系统中漫无边际的搜索,只需要看看这个类有没有相应函数即可(内聚性是多么重要)。如果没有,则添加一个,首先满足了自己,别人如果需要,当然也可以复用。
所以,我们可以其修改为如下的样子:
struct Rectangle
{
// ...
unsigned int getArea() const
{
return width * height;
}
unsigned int getPerimeter() const
{
return 2 * (width + height);
}
private:
unsigned int width;
unsigned int height;
};
有了这样的定义之后,此类的用户甚至都不用到类的定义处去查看接口。在IDE的帮助下,程序员可以迅速判断自己所需的接口是否存在:
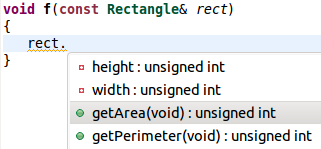
有了类的封装,Rectangle的客户将不再可能编写重复的算法:
void f1(const Rectangle& rect)
{
unsigned int area = rect.getArea();
// ...
}
void f2(const Rectangle& rect)
{
unsigned int perimeter = rect.getPerimeter();
// ...
}
void f3(const Rectangle& rect)
{
unsigned int area = rect.getArea();
// ...
}
IDE对于效率的影响
多年前我刚刚加入ThoughtWorks时,有幸与PicoContainer的作者Jon Tirson一个团队,并与他结对编程。第一次结对,我就被他神一般的编码速度所震惊:大手一抹,整片的Java代码就出现在屏幕上。
震惊之余,我开始仔细观察他是如何做到的:除了他确实敲键盘的速度很快之外,他对IDE的应用极其熟练:各种热键,代码模版用的滚瓜烂熟,并非常善于利用IDE的提示信息等等。
在静态面向对象语言里,class作为行为的载体,会非常方便于IDE给出程序员提示信息。这对于程序员的高效编码极有帮助。(这也是我在进行C或者Haskell编程时,很多函数名都必须靠自己记忆,而不是靠IDE帮助,感觉特别不爽的原因)。
提高内聚性
我们通过一个例子:Maybe问题,来看看封装如何有利于提高包括数据自身的内聚性的。
每个C和C++程序员都处理过空指针问题。比如,我们在一个单向链表的典型实现中,我们会让对象持有一个指向下一个对象的指针:
struct Object
{
void f();
void g();
Object* next; // 指向下一个节点的指针
// ...
};
其中,next指针为空是一种合法的情况,它表示当前对象是单向链表中的最后一个节点。所以,我们可能会编写如下的代码:
void Object::f()
{
// ...
if(next != 0)
{
next->g();
}
// ...
}
所以,任何一个指针,事实上都包含了两种语义:
- 指针是否有效(是否是一个空指针);
- 其二,如果有效,它的值是什么(指向哪个对象)。
指针天然就存在这样的双重语义,而其它类型则不然。但程序员们可以通过自定义的方式,为其它类型引入这种双重语义。
比如,程序员们经常选择0xffffffff当作uint32_t类型的“空指针”。比如:
const u32 INVALID_VALUE = 0xffffffff;
// ...
void f(const u32 value)
{
if(value != INVALID_VALUE)
{
// 使用 value 进行进一步的运算
g(value * 5);
}
// ...
}
但无论是空指针,还是自定义无效数值,都并非在所有场景下都适用。
比如, 系统并不想通过动态分配内存的方式来分配对象,所以,你无法使用空指针来区分数据的有效性。而对于整数来说,如果其取值范围内的所有数值都是有效数值,你也不可能找个一个数值来代表无效数值。
这种情况下,程序员们往往会选择专门用一个bool型的标志来标示数据的有效性。比如:
struct Object
{
void f();
// ...
Foo foo; // 不想动态分配内存
bool isFooEffective;
u32 value; // [0, 0xffffffff] 均为有效值
bool isValueEffective; // ...
};
对于这类数据的操作模式往往是:
void Object::f()
{
int result = 0;
if(isValueEffective)
{
result += value;
}
if(isFooEffective)
{
result += foo.getValue();
}
// ...
}
这种一分为二的方法,还原了事情的原貌:本来它们就是双重语义。
但这种语义的分离却带来一个缺点。毫无疑问,这两个语义是紧密关联的,任何一个离开另外一个都让原有的语义不再完整。但从形式上,这种紧密的关联性却没有得到任何体现,只有通过仔细分析代码,才可以确定这种关联性。这无疑会伤害代码的可理解性。
解决这个问题的办法,当然是再将它们合在一起,形成一个完整的概念: Maybe。
template <typename T>
struct Maybe
{
Maybe()
: effective(false)
{}
Maybe(const T& data)
: data(data), effective(true)
{}
bool isEffective() const
{
return effective;
}
T* operator->()
{
return effective ? &data : 0;
}
const T* operator->() const
{
return effective ? &data : 0;
}
T& operator*()
{
return *(operator->());
}
const T& operator*() const
{
return *(operator->());
}
void clear()
{
effective = false;
}
// ...
private:
T data;
bool effective;
};
借助这个定义,之前的那些定义就可以改变为:
struct Object
{
// ...
Maybe<Foo> foo;
Maybe<u32> value;
// ...
};
然后,对于Maybe类型的数据访问方式也改变为:
void Object::f()
{
int result = 0;
if(value.isEffective())
{
result += (*value);
}
if(foo.isEffective())
{
result += foo->getValue();
}
// ...
}
如果你仔细观察,就会发现:通过Maybe这样的定义,我们又重新恢复了空指针语义。每一个Maybe类型的数据都是一个指针,只有在有效的情况下,才可以对指针指向的内容进行访问,否则,对其访问将会引起异常。
另外,这种实现方式,并没有简化客户代码,它仍然需要使用if结构来确定数据的有效性,然后再对数据进行访问,这和原有方式的复杂度是一样的。但这种方式的关注点在于,通过将两个分散的变量定义(数据和有效性标志)合二为一,形成一个更明确的概念,以提高代码的表现力,增强可理解性。
另外,在原有方式下,程序员需要考虑每一个标志的命名,并要确保在逻辑判断处引用了对应的标志;并且,当需要删除一个数据时,也需要同时考虑删除其对应的标志,这都给可维护性带来更多代价。而Maybe则统一了这类问题的操作方式,从而让程序员在编写,阅读和维护这类代码时,免除了上述的麻烦。
Setter
一个类不管三七二十一,都直接提供对所有数据成员的Setter接口,很多时候,像Getter一样,都是将不稳定的内部实现细节进行暴露的方式。
但Setter问题也并不都是邪恶的。为了说明这个问题,让我们再次回到Rectangle的例子:
struct Rectangle
{
Rectangle
( unsigned int width
, unsigned int height)
: width(width)
, height(height)
{}
unsigned int getArea() const
{ return m_width * m_height; }
unsigned int getPerimeter() const
{ return m_width * m_height; }
private:
unsigned int width;
unsigned int height;
};
此类所构造出来的对象,都是Immutable的:其状态自从构造后,就再也不可修改。
如果Immutability正是对Rectangle的要求,那么你绝不应该擅自增加对于width和height的Setter接口。
但如果我们随后从需求上确实要求能够修改其长度和宽度,那就不得不增加相应的Setter:
struct Rectangle
{
Rectangle
( unsigned int width
, unsigned int height)
: width(width)
, height(height)
{}
void setWidth(unsigned int width)
{ m_width = width; }
void setHeight (unsigned int height)
{ m_height = height; }
// ...
private:
unsigned int width;
unsigned int height;
};
这样的Setter在需求的驱动下,并没有什么危害性。最主要的原因在于,Width和Height本来就是一个Rectangle的稳定属性。
另外,在本例中,构造函数和Setter方法,看起来都是为了给成员变量赋值。它们似乎是可以相互替代的赋值手段,其差异不过是:构造看起来要比Setter更简洁。
这是一种完全错误的看法。两者从任何一个角度看,都是完全不同的两类事物。
首先,两者的客户不同:构造函数面向的用户是Creator,而其它成员函数的用户则是类服务需要者,即类真正的Clients。
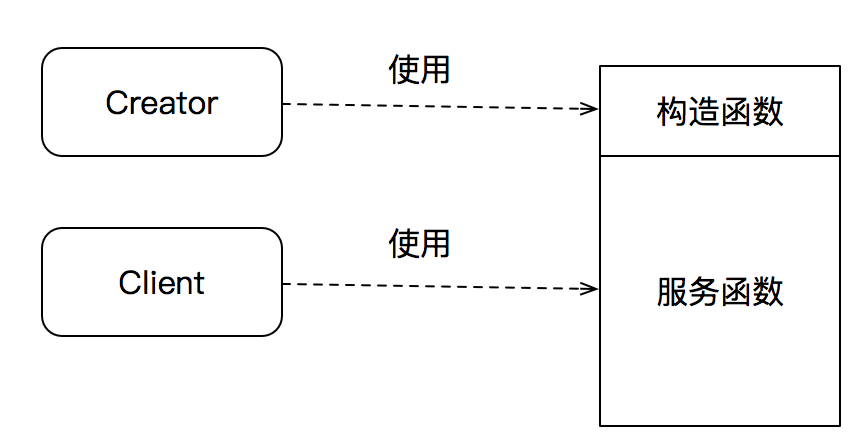
尽管可以由单个类同时承担,但Creator和Clients本质上是两种完全不同的角色。在需要分离不同变化方向时的时候,Creator和Client经常由不同的类来扮演。
其次,当一个类实例被构造完成时,就应该能够表现它所表现的对象。比如,当Rectangle rect(3,4)执行结束后,实例rect就应该能够代表一个宽为3,高为4的Rectangle。
而表达式Rectangle rect构造出的rect其实什么都不是。它无法履行它的职责,即无法表现一个合法的矩形。
所以,构造函数的目的,是为了创造出一个合法的、能够履行职责的、能够代表它要表现的概念实例。
而Setter函数,则是提供给Client的一个状态变更接口。它的存在,完全取决于客户是否需要。从这个意义上,Setter和任何其它服务函数没有任何差别。
所以,构造和Setter并非二选一的关系,而是为不同目的存在、完全没有任何关系的两套接口。它们可以同时存在,也可以根据需要选择其中任何一种。
以Rectangle为例,通过构造函数来得到合法的Rectangle实例是必须的。如果没有任何状态变更的需要,那么在构造结束后,我们就得到了一个值对象(Value Object)。而一个值对象的成员函数,除了构造和析构,都应该有const修饰。构造时赋值是设置值对象状态的唯一时机。
如果。随后Client要求一个状态变更接口,无论是否是Setter,只要可能改变实例的状态,那么它就是一个普通对象。
总结
面向对象的主要目的是为了模块化。而封装作为OO的三大特征之一,其主要目的,是在模块化的过程中通过信息隐藏,封装变化,从而提高系统应对变化的能力。
本文通过几个例子,从不同侧面讲述了关于封装的作用和方法。而关于如何做好封装,总是可以回到高内聚低耦合的角度来思考,通过正交策略来指导。
相关链接
其它与封装有关的话题:《容器与封装》
关于变化:《第一颗子弹》
关于OO的目的: 《正交设计: OO与SOLID》
关于如何避免过度设计:《简单设计》
