在目前所使用的数据处理软件中,关系数据库管理系统(Relation Database Management System,RDBMS)占据了统治地位。它代表了第二代数据库管理系统,它是基于 E. F. Codd (1970)所提出的关系数据模型。在关系模型中,所有数据逻辑上被组织成 关系(表)结构。每个关系都有自己的名称,并由数据的一些命名 属性(表中的列)所组成。每个 元组(表中的行)包含每个属性的一个取值。关系模型的最大优点在于其逻辑结构简单。但这种简单的结构却有着可靠地理论基础,这正是第一代 DBMS 所欠缺的。
1.关系数据结构
关系(relation):关系是由行和列组成的表。
RDBMS 要求用户感知到的数据库就是表。但需注意,这种感知只限于数据库的逻辑结构,就是 ANSI-SPARC 结构的外部层和概念层。它并不适用于数据库的物理结构,数据库的物理结构是通过多种存储结构实现的。属性(property):属性是关系中命名的列。
在关系模型中,用 关系 保存数据库所描述对象的信息。关系用二维表表示,表中的每行对应一个单独的记录,表中的每一列则对应一个 属性 。无论属性如何排列,都是同一个关系,因此它所表达的意思也一样。域(field):域是一个或多个属性的取值集合。
域在关系模型中起着至关重要的作用。必须给关系中的每一个属性定义一个域。不同属性可以互不相同,也可以让两个或两个以上的属性共用同一个域。元组(tuple):关系中的每一行称为元组。
关系的元素就是表中的行或者说是 元组。无论元组如何排列,都是同一个关系,因此所表达的意思也一样。关系的结构、域说明以及所有取值约束,统称为关系的 内涵(intension),它通常是固定的,除非关系的意义发生改变而需要加入另外的属性。元组集称为关系的 外延(extension)或 状态(state),它经常发生改变。维数:关系的维数是指关系所包含属性的个数。
只有一个属性的关系的维数为1,称为 一元 关系或是一元组。有两个属性的关系称为 二元 关系,有三个属性的关系称为 三元 关系,这之后的一般统称为 n元 关系。关系的维数是关系 内涵 的性质之一。基数:关系的基数指的是它所包含的元组的个数。
反过来说,元组的个数称为关系的基数,在添加或删除元组时,基数就会发生改变。基数是关系 外延 的一个性质,它由给定时刻特定的关系实例所决定。关系数据库(relational database):关系数据库是具有不同关系名的规范化关系的集合。
关系数据库包含一组有合适结构的关系。这种合适性称为 规范化。
可选术语

2. 数学中的关系
假设有两个集合 D1 和 D2,其中
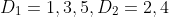
这两个集合的笛卡尔积是一个有序对的集合,每个有序对中的第一个元素都是D1中的成员,第二个元素是D2中的成员,D1 X D2 包含了所有这样的有序对。换一种表达方式就是,找出所有第一个元素来自 D1、第二个元素来自 D2 的元素组合。在这个例子中可以得出:
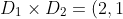, (2, 3), (2, 5), (4, 1), (4, 3), (4, 5)})
这个笛卡尔乘积的任何子集都是一个关系。例如,可以找到如下的一个关系 R:
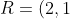, (4, 1)})
可以通过一些选择条件来说明关系中将会有哪些有序对。例如,如果看出R是所有第二个元素为1的有序对的集合,就能够将 R 表示成:
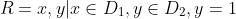
使用同样的集合D1、D2,还可以形成另一种关系S,它包含所有这样的有序对,其中第一个元素是第二个元素的两倍。因此,可以将 S 表示如下:
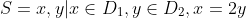
或者,用这个实例,
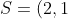})
因为在这个笛卡尔积中只有一个有序对满足此条件。可以简单地将关系的概念扩展到三个集合上。假设有三个集合D1,D2,D3。这三个集合的笛卡尔乘积将是所有这样的有序三元组的集合,有序三元组从 D1 中取出第一个元素,从 D2 中取出第二个元素,从 D3 中取出第三个元素。这个笛卡尔乘积中的任何子集也是一个关系。例如,假设有:
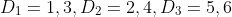
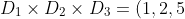, (1, 2, 6), (1, 4, 5), (1, 4, 6), (3, 2, 5), (3, 2, 6), (3, 4, 5), (3, 4, 6)})
这些有序三元组的任何子集都是一个关系。可以继续将三集合扩展,从而定义 n 个域上的一般关系。设D1,D2.....Dn 为 n 个集合。它们的笛卡尔乘积定义如下:
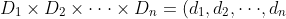|d_1 \in D_1, d_2 \in D_2, \cdot \cdot \cdot ,d_n \in D_n})
通常被表示成:
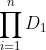
这个笛卡尔积中任何 n 元组的子集都是这 n 个集合上的一个关系。注意,为了定义这些关系,必须对取值集合(即域)进行说明。
3. 数据库中的关系
将上面所介绍的概念应用到数据库当中,就可以定义关系模式。
- 关系模式:用一组属性和域名对定义的具名的关系。
- 关系数据库模式:关系模式的集合,集合中的每个关系都应有不同的名字。
4. 关系的性质
一个关系通常有如下性质:
- 有一个关系名,同一关系模式中各关系不能重名。
- 关系中的每一个单元格都确切包含一个原子(单个)值。
- 每个属性都有一个不同的名字。
- 同一属性中的各个值都取自相同的域。
- 各元组互不相同,不存在重复元组。
- 属性的顺序并不重要。
- 理论上讲,元组的顺序也不重要(但实际上,这个顺序将影响对元组的访问效率)。
现在说明这些限制的含义,关系不能包含重复组。满足这一性质的关系称为 规范化 关系或 第一范式 关系。
关系的大部分特有性质都源于数学中关系的性质:
- 当用简单的、单值元素(如整数)的集合导出笛卡尔积时,每个元组中的所有元素都是单值的。类似的,关系的每个单元格中也只包含一个单值。但数学意义上的关系无需规范化。Codd 强调不允许重复组的出现是为了简化关系数据模型。
- 在数学关系中,某一位置的可能取值由定义该位置的集合或域来决定。对应的,在表中每一列的取值必须源自相同的属性域。
- 集合中没有重复元素。同样,关系中没有重复的元组。
- 因为关系是用集合定义的,集合中元素的顺序无关紧要,因此,关系中元组的顺序也就没有实质意义了。
但在数学关系中,元组中各个元素的顺序是很重要的。例如,有序对(1,2)与有序对(2,1)就大不相同。而对于关系模型中的关系则不一样,它明确要求属性的顺序不具备实际意义。原因就在于每一列的标题一说明了该列的值对应哪个属性。这就意味着,关系内涵中列标题的顺序无关紧要,不过一旦选定了关系的结构,其外延中元组的元素顺序就必须与属性名的顺序相一致。
5. 关系关键字
如前所述,关系中不会出现重复的元组。因此,可以指定一个或多个属性(称为关系关键字),唯一的标识关系中的每个元组。如下所示关系Branch和关系Staff的实例:

超关键字(superkey):一个属性或属性集合,它能唯一地标识出关系中的每个元组。
超关键字能唯一标识关系中的每个元组。但超关键字中有可能包含多余属性,但在一般情况下,人们仅对能唯一标识元组的最小属性集合感兴趣。-
候选关键字(candidate key):本身是超关键字但其任何子集都不在是超关键字。
关系 R 中的候选关键字 K 有两条性质:- 唯一性:R 中的每个元组在 K 上的值都可以唯一的标识该元组。
- 不可约性:K 中的任一真子集都不具备唯一性。
一个关系中可能会有多个候选关键字。当一个关键字中包含多个属性时,就称它为 合成关键字。考虑上图所示的关系 Branch。给定一个 city 属性的值,可以确定出几个分公司(例如,在 London 有两个分公司)。这个属性不能作为候选关键字。另一方面,因为 DreamHome 给每个分公司分配了唯一的分公司编号,那么给定的一个分公司编号值 branchNo,则可以确定至多一个元组,因此 branchNo 就是一个候选关键字。同样,postcode 也是这个关系中的候选关键字。
现在假设有关系 Viewing,它包含客户查看房产的相关信息。这个关系中包括客户编号(clientNo)、房产编号(propertyNo)、查看日期(viewDate),还有一个可选择填写的属性——对房产的评论(comment)。给定一个客户编号 clientNo,他可能查看过几处不同的房产,所以会有几条记录与之对应。同样,给定一个房产编号 propertyNo,也可能会有多个客户看过该房产。因此,clientNo 和 propertyNo 都不能单独地作为候选关键字。但如果把 clientNo 和 propertyNo 结合起来,则至多可标识一个元组,因此,对于 Viewing 关系而言,clientNo 和 propertyNo 一起形成了一个(组合)候选关键字。如果允许客户对同一房产查看多次,则可以在组合关键字中添加 viewDate 属性。
注意,一个关系实例无法证明某个属性或某几个属性的组合能否作为候选关键字。事实上,在某个特定时刻,没有重复出现的值并不能保证永远不重复。但在一个关系实例中就出现重复值的属性或属性组合肯定不能作为候选关键字。确定候选关键字时,必须明确这些属性在 “现实世界” 中的含义,从而确保不会出现重复。只有通过这种语义信息才能确定一种属性组合是否可以作为候选关键字。例如,在 Staff 关系中,可能认为lName(姓氏)适合作为关系 Staff 的候选关键字。显然,在关系 Staff 的这个实例中虽然只有一个姓 White 的员工,但完全可能会有一个同样姓 White 的新员工加入公司,那时 lName 作为候选关键字就无效了。
主关键字(Primary key):被选用于唯一标识关系中各元组的候选关键字。
因为关系中没有重复元组,所以总可以唯一的标识出每一行。这就意味着,每个关系总有一个主关键字。最糟糕的情况是属性全集作为主关键字,但一般都存在某个稍小的子集足以标识每个元组。没有被选为主关键字的候选关键字称为 可替换关键字(alternate key)。如果在关系 Branch 中选择 branchNo作为主关键字,postcode 就成了可替换关键字。对 Viewing 关系而言,它只有一个候选关键字,即 clientNo 与 propertyNo 的组合,因此这两属性的组合就自动地形成了主关键字。外部关键字(Foreign key):当一个关系中的某个属性或属性集合与另一个关系(也可能就是自己)的候选关键字匹配时,就称这个属性或属性集合为外部关键字。
当一个属性出现在两个关系中时,它往往表示这两个关系中对应元组之间的某种联系。例如,属性 branchNo 同时出现在关系 Branch 和 Staff 中,目的就是将每个分公司与在此分公司工作的员工联系起来。在关系 Staff 中,branchNo 就是一个外部关键字。或者说关系 Staff 中的属性 branchNo 指向 主关系 Branch 的 主关键字 ——属性 branchNo。这些公有属性在执行数据操作时将扮演重要角色。
6. 关系数据库模式的表示
关系数据库是由一些规范化关系所组成的。对应 DreamHome 案例的部分关系模式如下:
| relation | property |
|---|---|
| Branch | (<u>branchNo</u>, street, city, postcode) |
| Staff | (<u>saffNo</u>,fName, lName, position, sex, DOB, salary, branchNo) |
| PropertyForRent | (<u>propertyNo</u>, street, city, postcode, type, rooms, rent, ownerNo, staffNo, branchNo) |
| Client | (<u>clientNo</u>, fName, lName, telNo, prefType, maxRent, eMail) |
| PrivateOwner | (<u>ownerNo</u>, fName, lName, address, telNo, eMail, password) |
| Viewing | (<u>clientNo</u>, <u>propertyNo</u>, viewDate, comment) |
| Registration | (<u>clientNo</u>, <u>branchNo</u>, staffNo, dateJoined) |
关系模式的习惯表示法是,给出关系名,并在后面的圆括号中列出关系的属性名。一般用下划线标出主关键字。概念模型(或者说概念模式)是指数据库中所有这种模式的集合。
