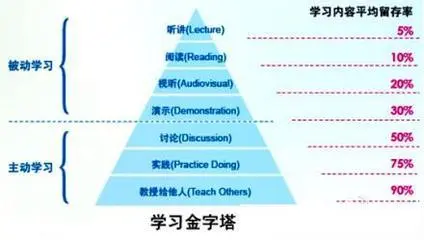
从DPG到D4PG 前文提到的AC算法,策略函数表示的是,在当前状态下,动作空间的概率分布,然后通过采样选择动作,即策略是随机不确定的。那可否在连续动作空间内像DQN一样采取...
 发简信
发简信
IP属地:浙江

从DPG到D4PG 前文提到的AC算法,策略函数表示的是,在当前状态下,动作空间的概率分布,然后通过采样选择动作,即策略是随机不确定的。那可否在连续动作空间内像DQN一样采取...

以DQN为代表的绝大多数基于值的方法通过求解最优值函数+选择当前价值最高的动作来实现。策略高梯度算法则从另一个角度展开——将策略参数化为,直接通过优化参数来最大化累计回报的期...

发个库存,嘻嘻,这篇主要讲AC类算法 演员-评论家算法(Actor-Critic) 上文公式中我们采用的累计回报和(),虽然它是期望收益的无偏估计,但由于只使用了一个样本,存...